XXHash
XXHash is a fast (the XX stands for extremely) hash algorithm designed by Yann Collet which can hash data faster than it can be copied. This is not unreasonable: copying memory requires that the data be both read and written, yet producing a hash can get away with just reading the data; the result is of negligible size. Nevertheless, XXHash, which is used as the checksum in the LZ4 frame format, and its 64 bit variant XXHash64, are extremely fast hashing algorithms.
The algorithm is fast (and only faster than alternatives for larger inputs) for two reasons:
- Hashing one
byteat a time is slow: much faster to hashints orlongs. - Multiplications are slow but can be pipelined to remove data dependencies: replace total order with partial order.
The XXHash algorithms separate the input stream of bytes into four independent streams: each 32 bits wide in XXHash32; 64 bits wide in XXHash64. The same operations are applied to the elements of each stream in sequence. For XXHash32:
- Interpret the next four
bytes as anint. - Multiply the
intby a primep2. - Add the result to the result of the last iteration for the same stream, or a seed value if it is the first iteration.
- Rotate the result left by 13 bits. Recall that this is equivalent to
(x >>> -13) | (x << 13). - Multiply the result by another prime
p1. - Store the result for the stream.
For reference, here’s the 32 bit version written in Java, adapted from an implementation in lz4-java, with the bullet points above labeled as the “main loop”.
public int hash(byte[] data, int seed) {
int end = data.length;
int offset = 0;
int h32;
if (data.length >= 16) {
// main loop starts
int limit = end - 16;
int v1 = seed + PRIME1 + PRIME2;
int v2 = seed + PRIME2;
int v3 = seed;
int v4 = seed - PRIME1;
do {
v1 += getInt(data, offset) * PRIME2;
v1 = Integer.rotateLeft(v1, 13);
v1 *= PRIME1;
offset += 4;
v2 += getInt(data, offset) * PRIME2;
v2 = Integer.rotateLeft(v2, 13);
v2 *= PRIME1;
offset += 4;
v3 += getInt(data, offset) * PRIME2;
v3 = Integer.rotateLeft(v3, 13);
v3 *= PRIME1;
offset += 4;
v4 += getInt(data, offset) * PRIME2;
v4 = Integer.rotateLeft(v4, 13);
v4 *= PRIME1;
offset += 4;
} while(offset <= limit);
// main loop ends
// mix
h32 = Integer.rotateLeft(v1, 1) + Integer.rotateLeft(v2, 7) + Integer.rotateLeft(v3, 12) + Integer.rotateLeft(v4, 18);
} else {
h32 = seed + PRIME5;
}
for(h32 += data.length; offset <= end - 4; offset += 4) {
h32 += getInt(data, offset) * PRIME3;
h32 = Integer.rotateLeft(h32, 17) * PRIME4;
}
while(offset < end) {
h32 += (data[offset] & 255) * PRIME5;
h32 = Integer.rotateLeft(h32, 11) * PRIME1;
++offset;
}
h32 ^= h32 >>> 15;
h32 *= PRIME2;
h32 ^= h32 >>> 13;
h32 *= PRIME3;
h32 ^= h32 >>> 16;
return h32;
}
For the 64 bit version, the steps for processing the substreams are identical, except each stream is 8 bytes wide and the rotation is by 31.
While the rotations are fast, the multiplications in the main loop have high latency, which could be a bottleneck in the presence of data dependencies, but the processing of each stream is pipelined by modern processors. Rather than stall during the multiplications, the rotations and data loads advance, which makes the loop fast; faster than copying memory. At the end, roughly, the intermediate hashes are combined to create a single hash value, but the state at any point during the main loop is a 4-element vector.
Vectorised XXHash?
The 32-bit algorithm can be vectorised with AVX2 instructions: all of add, multiply, rotate left (which decomposes to left shift, or, and right logical shift) can be written in terms of vector instructions. However, unlike polynomial hash codes which I demonstrated how to vectorise, there’s no obvious way to collect together what I will refer to as the “scrambling operations” - the multiplications and the shifts in this case - which means that one iteration of the loop must be evaluated before the next can start. This is a hard limit on the scalability of the algorithm: even if you have an eight lane AVX2 vector or a 16 lane AVX512 vector, only four lanes can be used.
The vectorised algorithm is visualised quite roughly below, from splitting the input data into substreams, seed initialisation, through the vectorised operations, skipping over mixing the hash at the end.
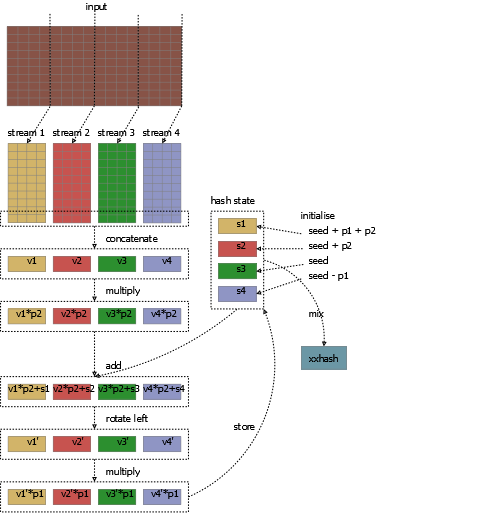
It’s surprisingly easy to translate the Java code above to use the current incarnation of the Project Panama Vector API; it actually simplifies the code a lot. The implementation specifically targets 128-bit vectors, because it would be incorrect not to.
public class VectorXXHash32 implements Hasher32 {
private static final VectorSpecies<Integer> I128 = VectorSpecies.of(int.class, VectorShape.S_128_BIT);
private static final VectorSpecies<Byte> B128 = VectorSpecies.of(byte.class, VectorShape.S_128_BIT);
private static final int[] SEEDS = {PRIME1 + PRIME2, PRIME2, 0, -PRIME1};
@Override
public int hash(byte[] data, int seed) {
int end = data.length;
int offset = 0;
int h32;
if (data.length >= 16) {
int limit = end - 16;
var vector = ((IntVector) I128.fromArray(SEEDS, 0)).add(seed);
do {
vector = vector.add(B128.fromArray(data, offset).reinterpretAsInts().mul(PRIME2))
.lanewise(ROL, 13)
.mul(PRIME1);
offset += 16;
} while(offset <= limit);
// mixing
h32 = Integer.rotateLeft(vector.lane(0), 1)
+ Integer.rotateLeft(vector.lane(1), 7)
+ Integer.rotateLeft(vector.lane(2), 12)
+ Integer.rotateLeft(vector.lane(3), 18);
} else {
h32 = seed + PRIME5;
}
for(h32 += data.length; offset <= end - 4; offset += 4) {
h32 += getInt(data, offset) * PRIME3;
h32 = Integer.rotateLeft(h32, 17) * PRIME4;
}
while(offset < end) {
h32 += (data[offset] & 255) * PRIME5;
h32 = Integer.rotateLeft(h32, 11) * PRIME1;
++offset;
}
h32 ^= h32 >>> 15;
h32 *= PRIME2;
h32 ^= h32 >>> 13;
h32 *= PRIME3;
h32 ^= h32 >>> 16;
return h32;
}
}
XXHash64 cannot be vectorised in AVX2, because there isn’t a 64-bit vector multiplication in that instruction set, but the loads, additions and rotations can all be vectorised.
It can be vectorised in AVX512, where packed multiplication of longs is supported: _mm256_mullo_epi64.
The widest vector unit supported by an AVX-512-capable platform (e.g. LongVector.SPECIES_PREFERRED) would not be the right choice in this case.
I ran some benchmarks for VectorXXHash32 as seen above, but didn’t get great results, despite the Vector API doing precisely what it was told to do. The hot part of the loop is here:
0.02% ││↗ 0x00007f044c0848a0: mov %r9d,%r10d
│││
│││
│││
│││
│││
│││
6.59% │↘│ 0x00007f044c0848a3: vmovdqu 0x10(%r13,%r10,1),%xmm0
0.11% │ │ 0x00007f044c0848aa: vpmulld %xmm4,%xmm0,%xmm0
0.15% │ │ 0x00007f044c0848af: vpaddd %xmm0,%xmm3,%xmm0
7.49% │ │ 0x00007f044c0848b3: vpsrld %xmm1,%xmm0,%xmm3
20.83% │ │ 0x00007f044c0848b7: vpslld %xmm2,%xmm0,%xmm5
4.66% │ │ 0x00007f044c0848bb: vpor %xmm3,%xmm5,%xmm0
│ │
│ │
1.43% │ │ 0x00007f044c0848bf: vpmulld %xmm6,%xmm0,%xmm3
│ │
│ │
│ │
│ │
49.45% │ │ 0x00007f044c0848c4: mov %r10d,%r9d
0.10% │ │ 0x00007f044c0848c7: add $0x10,%r9d
0.04% │ │ 0x00007f044c0848cb: cmp %r8d,%r9d
│ ╰ 0x00007f044c0848ce: jl 0x00007f044c0848a0
Notice the ~49% profile attributed to the mov instruction: this is skid from the slow multiplication, similarly the ~21% attributed to vpslld. Here, fast instructions are sandwiched between slow instructions, and no unrolling is possible because the loop doesn’t have separable coefficients. Fusing the multiplications into a single instruction actually makes this loop go in lock-step, where the four chains of the scalar loop would be free to advance independently, and the latency of the multiplications cannot be amortised by pipelining. Just having access to vectors doesn’t mean code will automatically be faster.
Besides, the vector isn’t very wide. I also implemented VectorXXHash64 and if I had sudoer access to a machine with AVX512 I would be interested to see how it does - I will try it later in the year when I replace my development machine with an Icelake machine.
Byte Packing Without Unsafe!
It’s impossible to implement XXHash32/64 without packing bytes into wider types.
Packing bytes into ints and longs is suboptimal when endianness is known, resulting in a lot more work than necessary.
This demonstrably limits the performance of some code in the JDK, such as DataInputStream.
This limitation even applied to ByteBuffer in JDK8, but the situation was improved in JDK9, replacing manual assembly of words from bytes with calls to Unsafe.getLongUnaligned.
As mentioned in my last post, there is often an incentive to break the rules and use Unsafe in application code, and every existing Java implementation of XXHash does this.
I hadn’t realised that since JDK9 there has been a VarHandle-based API to do this without Unsafe, so I tried it.
I wrote some benchmarks to measure the effect of how one chooses to assemble long and int from multiple bytes - I compared Unsafe.getLong, MethodHandles.byteArrayViewVarHandle, manual packing.
To demonstrate the cost of JNI, I threw in a baseline using the JNI wrapper in the excellent lz4-java library.
Credit: My benchmark code was inspired by existing implementations in LZ4-Java and Zero Allocation Hashing, just with template methods for varying the technique used to assemble words.
Here’s XXHash32, and MethodHandles.byteArrayViewVarHandle is (probably) within benchmark error of Unsafe, always performing better than doing it yourself or using JNI.
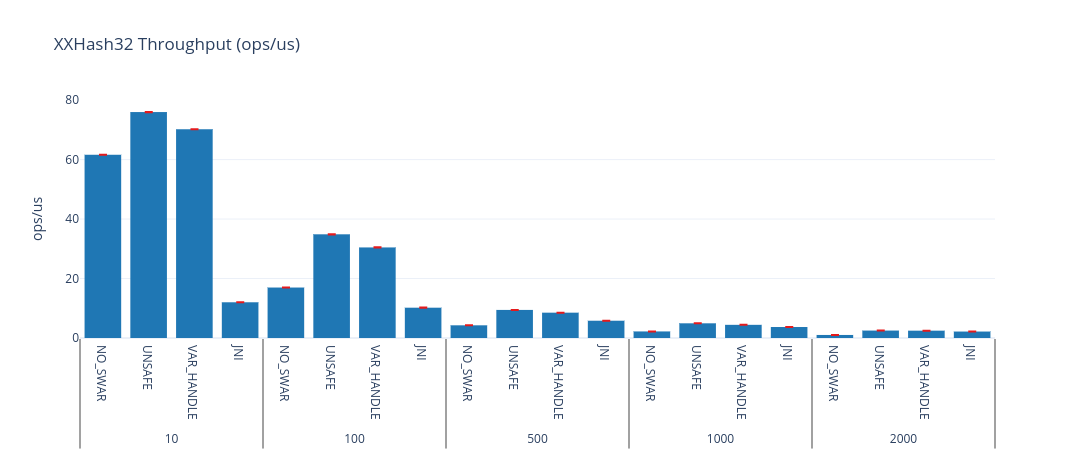
| Benchmark | Mode | Threads | Samples | Score | Score Error (99.9%) | Unit | Param: impl | Param: size |
|---|---|---|---|---|---|---|---|---|
| xxhash32 | thrpt | 1 | 5 | 61.616450 | 0.030470 | ops/us | NO_SWAR | 10 |
| xxhash32 | thrpt | 1 | 5 | 16.972429 | 0.019428 | ops/us | NO_SWAR | 100 |
| xxhash32 | thrpt | 1 | 5 | 4.267552 | 0.001809 | ops/us | NO_SWAR | 500 |
| xxhash32 | thrpt | 1 | 5 | 2.210332 | 0.000951 | ops/us | NO_SWAR | 1000 |
| xxhash32 | thrpt | 1 | 5 | 1.021404 | 0.000484 | ops/us | NO_SWAR | 2000 |
| xxhash32 | thrpt | 1 | 5 | 75.977642 | 0.052915 | ops/us | UNSAFE | 10 |
| xxhash32 | thrpt | 1 | 5 | 34.867256 | 0.021874 | ops/us | UNSAFE | 100 |
| xxhash32 | thrpt | 1 | 5 | 9.443314 | 0.003599 | ops/us | UNSAFE | 500 |
| xxhash32 | thrpt | 1 | 5 | 4.938806 | 0.003777 | ops/us | UNSAFE | 1000 |
| xxhash32 | thrpt | 1 | 5 | 2.501186 | 0.001733 | ops/us | UNSAFE | 2000 |
| xxhash32 | thrpt | 1 | 5 | 70.194848 | 0.030379 | ops/us | VAR_HANDLE | 10 |
| xxhash32 | thrpt | 1 | 5 | 30.455860 | 0.025935 | ops/us | VAR_HANDLE | 100 |
| xxhash32 | thrpt | 1 | 5 | 8.517298 | 0.009314 | ops/us | VAR_HANDLE | 500 |
| xxhash32 | thrpt | 1 | 5 | 4.427091 | 0.003145 | ops/us | VAR_HANDLE | 1000 |
| xxhash32 | thrpt | 1 | 5 | 2.463728 | 0.001364 | ops/us | VAR_HANDLE | 2000 |
| xxhash32 | thrpt | 1 | 5 | 12.010477 | 0.007089 | ops/us | JNI | 10 |
| xxhash32 | thrpt | 1 | 5 | 10.193501 | 0.051266 | ops/us | JNI | 100 |
| xxhash32 | thrpt | 1 | 5 | 5.811410 | 0.010683 | ops/us | JNI | 500 |
| xxhash32 | thrpt | 1 | 5 | 3.696106 | 0.002750 | ops/us | JNI | 1000 |
| xxhash32 | thrpt | 1 | 5 | 2.171261 | 0.001510 | ops/us | JNI | 2000 |
There’s a similar story for XXHash64: Unsafe still wins, but MethodHandles.byteArrayViewVarHandle is respectable - I expect it will take more and more justification to reach for Unsafe in future.
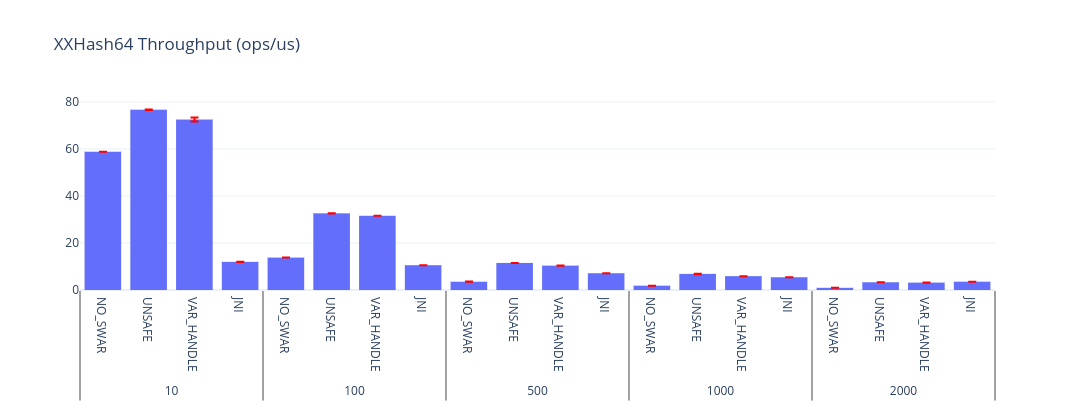
| Benchmark | Mode | Threads | Samples | Score | Score Error (99.9%) | Unit | Param: impl | Param: size |
|---|---|---|---|---|---|---|---|---|
| xxhash64 | thrpt | 1 | 5 | 58.808641 | 0.038382 | ops/us | NO_SWAR | 10 |
| xxhash64 | thrpt | 1 | 5 | 13.785868 | 0.008983 | ops/us | NO_SWAR | 100 |
| xxhash64 | thrpt | 1 | 5 | 3.527638 | 0.035888 | ops/us | NO_SWAR | 500 |
| xxhash64 | thrpt | 1 | 5 | 1.841760 | 0.001176 | ops/us | NO_SWAR | 1000 |
| xxhash64 | thrpt | 1 | 5 | 0.935639 | 0.000628 | ops/us | NO_SWAR | 2000 |
| xxhash64 | thrpt | 1 | 5 | 76.690206 | 0.082129 | ops/us | UNSAFE | 10 |
| xxhash64 | thrpt | 1 | 5 | 32.611361 | 0.028792 | ops/us | UNSAFE | 100 |
| xxhash64 | thrpt | 1 | 5 | 11.504606 | 0.004694 | ops/us | UNSAFE | 500 |
| xxhash64 | thrpt | 1 | 5 | 6.849572 | 0.114516 | ops/us | UNSAFE | 1000 |
| xxhash64 | thrpt | 1 | 5 | 3.289077 | 0.001559 | ops/us | UNSAFE | 2000 |
| xxhash64 | thrpt | 1 | 5 | 72.507878 | 0.814962 | ops/us | VAR_HANDLE | 10 |
| xxhash64 | thrpt | 1 | 5 | 31.566952 | 0.013733 | ops/us | VAR_HANDLE | 100 |
| xxhash64 | thrpt | 1 | 5 | 10.372298 | 0.018581 | ops/us | VAR_HANDLE | 500 |
| xxhash64 | thrpt | 1 | 5 | 5.891279 | 0.006254 | ops/us | VAR_HANDLE | 1000 |
| xxhash64 | thrpt | 1 | 5 | 3.138126 | 0.001611 | ops/us | VAR_HANDLE | 2000 |
| xxhash64 | thrpt | 1 | 5 | 11.968050 | 0.017392 | ops/us | JNI | 10 |
| xxhash64 | thrpt | 1 | 5 | 10.547767 | 0.013108 | ops/us | JNI | 100 |
| xxhash64 | thrpt | 1 | 5 | 7.136465 | 0.013838 | ops/us | JNI | 500 |
| xxhash64 | thrpt | 1 | 5 | 5.422707 | 0.007031 | ops/us | JNI | 1000 |
| xxhash64 | thrpt | 1 | 5 | 3.540314 | 0.002497 | ops/us | JNI | 2000 |
Of course, this is just data, and not reusable insight, but I’ll come back to this topic as soon as I have procured for myself an Icelake development environment.