Vectorised Byte Operations
I was encouraged to find out recently that many operations on byte[] can now be vectorised by C2 starting in JDK13.
These improvements come from a long line of contributions from Intel to improve C2’s use of AVX+ instructions, which have the potential of speeding up a lot of Java programs running on x86.
Naturally, I am keen to find out how big an impact this can have in an ideal situation, but also compare the simple routines with older, harder to get right, alternatives using Unsafe.
This post focuses on right logical or unsigned shift (>>>), and right arithmetic shift (>>), the latter preserving sign.
These operations aren’t necessarily very common in typical Java programs, but you might find the first operation in compression algorithms, and the second one in low precision signed arithmetic.
It doesn’t take much imagination to see these operations being useful in string processing, and the unsigned shift is used for extracting nibbles from bytes in a vector bit count algorithm.
I ran these benchmarks on my laptop, which has a mobile Skylake chip with AVX2, and runs Ubuntu 18.
This isn’t necessarily the best environment to run benchmarks, but is good enough to get a rough idea of the differences between releases, and gives access to diagnostic profilers.
I am comparing JDK11 with a JDK13 early access build downloaded here.
I looked at right logical shift first, which shifts all bits towards zero, and fills the most significant bits with zero.
@Benchmark
public void shiftLogical(ByteShiftState state, Blackhole bh) {
byte[] data = state.data;
byte[] target = state.target;
int shift = state.shift;
shiftLogical(data, target, shift);
bh.consume(target);
}
void shiftLogical(byte[] data, byte[] target, int shift) {
for (int i = 0; i < data.length; ++i) {
target[i] = (byte)((data[i] & 0xFF) >>> shift);
}
}
If you’re wondering why each individual value produced within the iteration isn’t consumed by the blackhole (a benchmark smell) it’s because the point of the benchmark is to look at which loop optimisations occur.
What’s that mask doing there?
Without masking, this operation makes no sense whatsoever because, by specification, the byte is cast to an int (with sign extension!) prior to the shift, casting back to byte after the shift, which means that the result can become negative.
It has always worked this way in Java, but this poses a question about backwards compatibility - is it always worth it? If any existing code contains unmasked shifts, is it really what the author intended?
In any case, I really hope Intel didn’t waste time vectorising this hare-brained operation so will only look at the masked shift, for which benchmarked throughput increased significantly in JDK13.
Below is a bar chart comparing throughputs for shiftLogical with JDK11 and JDK13, along with the raw data. The choice of sizes aims to capture the effects of post-loops by choosing a multiple of the vector width, as well as offsets to either side. Higher is better.
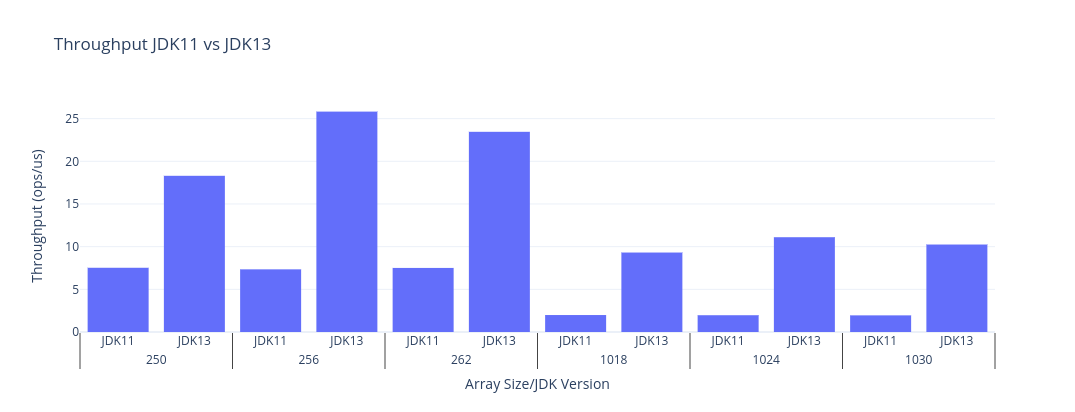
| JDK | Benchmark | Mode | Threads | Samples | Score | Score Error (99.9%) | Unit | Param: shift | Param: size |
|---|---|---|---|---|---|---|---|---|---|
| 13 | shiftLogical | thrpt | 1 | 5 | 18.191279 | 0.281667 | ops/us | 0 | 250 |
| 13 | shiftLogical | thrpt | 1 | 5 | 20.274241 | 0.482750 | ops/us | 0 | 256 |
| 13 | shiftLogical | thrpt | 1 | 5 | 23.666673 | 2.447062 | ops/us | 0 | 262 |
| 13 | shiftLogical | thrpt | 1 | 5 | 9.315800 | 0.289419 | ops/us | 0 | 1018 |
| 13 | shiftLogical | thrpt | 1 | 5 | 9.706462 | 0.275737 | ops/us | 0 | 1024 |
| 13 | shiftLogical | thrpt | 1 | 5 | 10.367262 | 0.183024 | ops/us | 0 | 1030 |
| 13 | shiftLogical | thrpt | 1 | 5 | 18.301114 | 1.095593 | ops/us | 1 | 250 |
| 13 | shiftLogical | thrpt | 1 | 5 | 25.823625 | 0.463037 | ops/us | 1 | 256 |
| 13 | shiftLogical | thrpt | 1 | 5 | 23.456042 | 0.533061 | ops/us | 1 | 262 |
| 13 | shiftLogical | thrpt | 1 | 5 | 9.311597 | 0.117147 | ops/us | 1 | 1018 |
| 13 | shiftLogical | thrpt | 1 | 5 | 11.106354 | 1.126994 | ops/us | 1 | 1024 |
| 13 | shiftLogical | thrpt | 1 | 5 | 10.250077 | 0.242414 | ops/us | 1 | 1030 |
| 13 | shiftLogical | thrpt | 1 | 5 | 18.609886 | 1.933992 | ops/us | 7 | 250 |
| 13 | shiftLogical | thrpt | 1 | 5 | 25.242200 | 0.667229 | ops/us | 7 | 256 |
| 13 | shiftLogical | thrpt | 1 | 5 | 23.111450 | 0.521140 | ops/us | 7 | 262 |
| 13 | shiftLogical | thrpt | 1 | 5 | 9.270754 | 0.563155 | ops/us | 7 | 1018 |
| 13 | shiftLogical | thrpt | 1 | 5 | 9.891347 | 0.052645 | ops/us | 7 | 1024 |
| 13 | shiftLogical | thrpt | 1 | 5 | 10.390528 | 0.225605 | ops/us | 7 | 1030 |
| 13 | shiftLogical | thrpt | 1 | 5 | 18.491362 | 0.388118 | ops/us | 8 | 250 |
| 13 | shiftLogical | thrpt | 1 | 5 | 25.319509 | 0.176510 | ops/us | 8 | 256 |
| 13 | shiftLogical | thrpt | 1 | 5 | 22.932418 | 0.470137 | ops/us | 8 | 262 |
| 13 | shiftLogical | thrpt | 1 | 5 | 9.363212 | 0.024503 | ops/us | 8 | 1018 |
| 13 | shiftLogical | thrpt | 1 | 5 | 10.879806 | 0.108640 | ops/us | 8 | 1024 |
| 13 | shiftLogical | thrpt | 1 | 5 | 10.552629 | 0.497255 | ops/us | 8 | 1030 |
| 11 | shiftLogical | thrpt | 1 | 5 | 7.519700 | 0.107267 | ops/us | 0 | 250 |
| 11 | shiftLogical | thrpt | 1 | 5 | 7.464531 | 0.308817 | ops/us | 0 | 256 |
| 11 | shiftLogical | thrpt | 1 | 5 | 7.473977 | 0.122781 | ops/us | 0 | 262 |
| 11 | shiftLogical | thrpt | 1 | 5 | 1.963351 | 0.061825 | ops/us | 0 | 1018 |
| 11 | shiftLogical | thrpt | 1 | 5 | 1.965883 | 0.139291 | ops/us | 0 | 1024 |
| 11 | shiftLogical | thrpt | 1 | 5 | 2.008736 | 0.188627 | ops/us | 0 | 1030 |
| 11 | shiftLogical | thrpt | 1 | 5 | 7.525109 | 0.047179 | ops/us | 1 | 250 |
| 11 | shiftLogical | thrpt | 1 | 5 | 7.341725 | 0.183424 | ops/us | 1 | 256 |
| 11 | shiftLogical | thrpt | 1 | 5 | 7.506334 | 0.127763 | ops/us | 1 | 262 |
| 11 | shiftLogical | thrpt | 1 | 5 | 1.987959 | 0.009052 | ops/us | 1 | 1018 |
| 11 | shiftLogical | thrpt | 1 | 5 | 1.966036 | 0.095510 | ops/us | 1 | 1024 |
| 11 | shiftLogical | thrpt | 1 | 5 | 1.949898 | 0.074998 | ops/us | 1 | 1030 |
| 11 | shiftLogical | thrpt | 1 | 5 | 7.571452 | 0.133089 | ops/us | 7 | 250 |
| 11 | shiftLogical | thrpt | 1 | 5 | 7.422129 | 0.542094 | ops/us | 7 | 256 |
| 11 | shiftLogical | thrpt | 1 | 5 | 7.429609 | 0.154287 | ops/us | 7 | 262 |
| 11 | shiftLogical | thrpt | 1 | 5 | 1.965460 | 0.076335 | ops/us | 7 | 1018 |
| 11 | shiftLogical | thrpt | 1 | 5 | 1.969899 | 0.096004 | ops/us | 7 | 1024 |
| 11 | shiftLogical | thrpt | 1 | 5 | 1.983031 | 0.016293 | ops/us | 7 | 1030 |
| 11 | shiftLogical | thrpt | 1 | 5 | 7.531941 | 0.139384 | ops/us | 8 | 250 |
| 11 | shiftLogical | thrpt | 1 | 5 | 7.367593 | 0.215386 | ops/us | 8 | 256 |
| 11 | shiftLogical | thrpt | 1 | 5 | 7.456574 | 0.160798 | ops/us | 8 | 262 |
| 11 | shiftLogical | thrpt | 1 | 5 | 2.027801 | 0.066184 | ops/us | 8 | 1018 |
| 11 | shiftLogical | thrpt | 1 | 5 | 2.096556 | 0.005543 | ops/us | 8 | 1024 |
| 11 | shiftLogical | thrpt | 1 | 5 | 1.948405 | 0.007283 | ops/us | 8 | 1030 |
This is a huge improvement in a minor JDK release - perhaps releasing two versions of Java per year is a good thing after all?
Here is the JDK13 vectorised loop body from perfasm (see vpsrlw):
0.29% ││││ │ 0x00007f0090365bf3: vmovdqu 0x10(%rdi,%r9,1),%ymm2
0.86% 0.58% ││││ │ 0x00007f0090365bfa: vextracti128 $0x1,%ymm2,%xmm4
0.57% 0.29% ││││ │ 0x00007f0090365c00: vpmovsxbw %xmm4,%ymm4
0.19% 1.16% ││││ │ 0x00007f0090365c05: vpmovsxbw %xmm2,%ymm5
0.19% 0.19% ││││ │ 0x00007f0090365c0a: vpsrlw %xmm3,%ymm4,%ymm4
2.30% 2.42% ││││ │ 0x00007f0090365c0e: vpsrlw %xmm3,%ymm5,%ymm5
1.25% 1.16% ││││ │ 0x00007f0090365c12: vpand -0x7ab00da(%rip),%ymm4,%ymm4 # Stub::vector_short_to_byte_mask
││││ │ ; {external_word}
1.15% 1.55% ││││ │ 0x00007f0090365c1a: vpand -0x7ab00e2(%rip),%ymm5,%ymm5 # Stub::vector_short_to_byte_mask
││││ │ ; {external_word}
0.96% 0.87% ││││ │ 0x00007f0090365c22: vpackuswb %ymm4,%ymm5,%ymm5
1.34% 0.58% ││││ │ 0x00007f0090365c26: vpermq $0xd8,%ymm5,%ymm5
3.35% 4.95% ││││ │ 0x00007f0090365c2c: vmovdqu %ymm5,0x10(%r11,%r9,1)
2.20% 1.75% ││││ │ 0x00007f0090365c33: vmovdqu 0x30(%rdi,%r9,1),%ymm2
0.10% ││││ │ 0x00007f0090365c3a: vextracti128 $0x1,%ymm2,%xmm4
0.96% 0.58% ││││ │ 0x00007f0090365c40: vpmovsxbw %xmm4,%ymm4
││││ │ 0x00007f0090365c45: vpmovsxbw %xmm2,%ymm5
1.53% 1.55% ││││ │ 0x00007f0090365c4a: vpsrlw %xmm3,%ymm4,%ymm4
1.05% 1.16% ││││ │ 0x00007f0090365c4e: vpsrlw %xmm3,%ymm5,%ymm5
1.72% 1.45% ││││ │ 0x00007f0090365c52: vpand -0x7ab011a(%rip),%ymm4,%ymm4 # Stub::vector_short_to_byte_mask
││││ │ ; {external_word}
0.10% ││││ │ 0x00007f0090365c5a: vpand -0x7ab0122(%rip),%ymm5,%ymm5 # Stub::vector_short_to_byte_mask
││││ │ ; {external_word}
1.05% 0.78% ││││ │ 0x00007f0090365c62: vpackuswb %ymm4,%ymm5,%ymm5
0.10% ││││ │ 0x00007f0090365c66: vpermq $0xd8,%ymm5,%ymm5
4.02% 3.69% ││││ │ 0x00007f0090365c6c: vmovdqu %ymm5,0x30(%r11,%r9,1)
And an extract from the much slower JDK11 scalar loop (see shr):
1.66% ││ 0x00007f30c4758943: movzbl 0x10(%r8,%rbp,1),%r11d
0.09% 0.09% ││ 0x00007f30c4758949: shr %cl,%r11d
1.29% 2.34% ││ 0x00007f30c475894c: mov %r11b,0x10(%rdi,%rbp,1)
0.18% ││ 0x00007f30c4758951: movzbl 0x11(%r8,%rbp,1),%r11d
0.09% ││ 0x00007f30c4758957: shr %cl,%r11d
2.68% ││ 0x00007f30c475895a: mov %r11b,0x11(%rdi,%rbp,1)
If you have ever needed to do something like this before and needed reasonable efficiency, you may have gone for a SIMD Within A Register (SWAR) approach using Unsafe.
In lower level languages like C, it’s possible to be ambivalent between integral types of different widths by casting, without any performance overhead.
In Java, it’s very costly to assemble a long from eight bytes, but it’s possible to take a similar approach to C programmers with Unsafe.
The code below does the same thing as the shiftLogical, but works on eight bytes at a time.
First the shift is applied, then a mask is applied to remove the flow of bits into the high end of each byte.
Since only nine shifts are possible (including zero and eight) the masks can be stored in a lookup table, written in binary rather than hex because it looks nice.
public static final long[] MASKS = new long[]{
0b1111111111111111111111111111111111111111111111111111111111111111L,
0b0111111101111111011111110111111101111111011111110111111101111111L,
0b0011111100111111001111110011111100111111001111110011111100111111L,
0b0001111100011111000111110001111100011111000111110001111100011111L,
0b0000111100001111000011110000111100001111000011110000111100001111L,
0b0000011100000111000001110000011100000111000001110000011100000111L,
0b0000001100000011000000110000001100000011000000110000001100000011L,
0b0000000100000001000000010000000100000001000000010000000100000001L,
0b0000000000000000000000000000000000000000000000000000000000000000L
};
Here is the SWAR implementation using Unsafe:
@Benchmark
public void shiftLogicalUnsafe(ByteShiftState state, Blackhole bh) {
byte[] data = state.data;
byte[] target = state.target;
int shift = state.shift;
shiftLogicalUnsafe(data, target, shift);
bh.consume(target);
}
void shiftLogicalUnsafe(byte[] data, byte[] target, int shift) {
long mask = MASKS[shift];
int i = 0;
for (; i + 7 < data.length; i += 8) {
long word = UNSAFE.getLong(data, BYTE_ARRAY_OFFSET + i);
word >>>= shift;
word &= mask;
UNSAFE.putLong(target, BYTE_ARRAY_OFFSET + i, word);
}
for (; i < data.length; ++i) {
target[i] = (byte)((data[i] & 0xFF) >>> shift);
}
}
This implementation does very little work, and is far superior to the straightforward approach in JDK11.
With JDK13, the straightforward code is so highly optimised that the gap is reduced to virtually nothing, and is faster for longer arrays, but the Unsafe version still wins for shorter arrays in this benchmark.
The chart below shows the benchmark results, where the red series is the measured throughput for each JDK version and array size (the higher the better), and the blue series is the advantage you would get from using Unsafe in each case. The raw data is below.
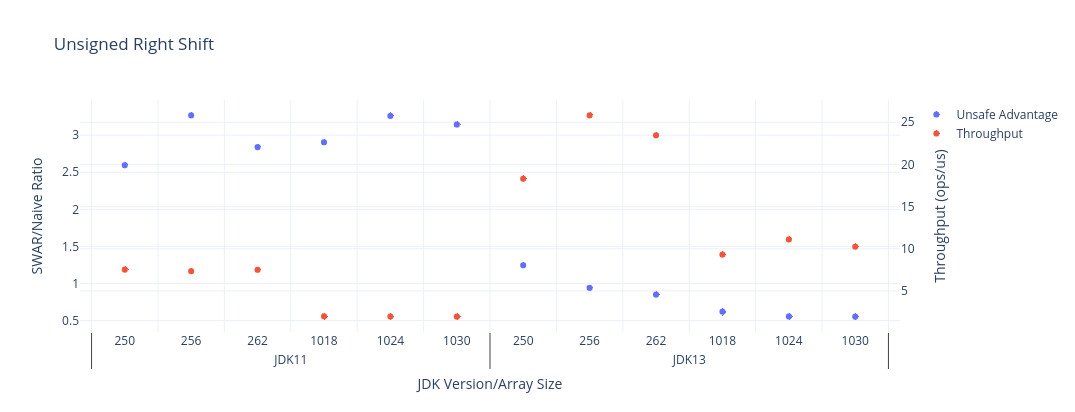
| JDK | Benchmark | Mode | Threads | Samples | Score | Score Error (99.9%) | Unit | Param: shift | Param: size |
|---|---|---|---|---|---|---|---|---|---|
| 13 | shiftLogical | thrpt | 1 | 5 | 18.191279 | 0.281667 | ops/us | 0 | 250 |
| 13 | shiftLogical | thrpt | 1 | 5 | 20.274241 | 0.482750 | ops/us | 0 | 256 |
| 13 | shiftLogical | thrpt | 1 | 5 | 23.666673 | 2.447062 | ops/us | 0 | 262 |
| 13 | shiftLogical | thrpt | 1 | 5 | 9.315800 | 0.289419 | ops/us | 0 | 1018 |
| 13 | shiftLogical | thrpt | 1 | 5 | 9.706462 | 0.275737 | ops/us | 0 | 1024 |
| 13 | shiftLogical | thrpt | 1 | 5 | 10.367262 | 0.183024 | ops/us | 0 | 1030 |
| 13 | shiftLogical | thrpt | 1 | 5 | 18.301114 | 1.095593 | ops/us | 1 | 250 |
| 13 | shiftLogical | thrpt | 1 | 5 | 25.823625 | 0.463037 | ops/us | 1 | 256 |
| 13 | shiftLogical | thrpt | 1 | 5 | 23.456042 | 0.533061 | ops/us | 1 | 262 |
| 13 | shiftLogical | thrpt | 1 | 5 | 9.311597 | 0.117147 | ops/us | 1 | 1018 |
| 13 | shiftLogical | thrpt | 1 | 5 | 11.106354 | 1.126994 | ops/us | 1 | 1024 |
| 13 | shiftLogical | thrpt | 1 | 5 | 10.250077 | 0.242414 | ops/us | 1 | 1030 |
| 13 | shiftLogical | thrpt | 1 | 5 | 18.609886 | 1.933992 | ops/us | 7 | 250 |
| 13 | shiftLogical | thrpt | 1 | 5 | 25.242200 | 0.667229 | ops/us | 7 | 256 |
| 13 | shiftLogical | thrpt | 1 | 5 | 23.111450 | 0.521140 | ops/us | 7 | 262 |
| 13 | shiftLogical | thrpt | 1 | 5 | 9.270754 | 0.563155 | ops/us | 7 | 1018 |
| 13 | shiftLogical | thrpt | 1 | 5 | 9.891347 | 0.052645 | ops/us | 7 | 1024 |
| 13 | shiftLogical | thrpt | 1 | 5 | 10.390528 | 0.225605 | ops/us | 7 | 1030 |
| 13 | shiftLogical | thrpt | 1 | 5 | 18.491362 | 0.388118 | ops/us | 8 | 250 |
| 13 | shiftLogical | thrpt | 1 | 5 | 25.319509 | 0.176510 | ops/us | 8 | 256 |
| 13 | shiftLogical | thrpt | 1 | 5 | 22.932418 | 0.470137 | ops/us | 8 | 262 |
| 13 | shiftLogical | thrpt | 1 | 5 | 9.363212 | 0.024503 | ops/us | 8 | 1018 |
| 13 | shiftLogical | thrpt | 1 | 5 | 10.879806 | 0.108640 | ops/us | 8 | 1024 |
| 13 | shiftLogical | thrpt | 1 | 5 | 10.552629 | 0.497255 | ops/us | 8 | 1030 |
| 13 | shiftLogicalUnsafe | thrpt | 1 | 5 | 22.077246 | 1.081037 | ops/us | 0 | 250 |
| 13 | shiftLogicalUnsafe | thrpt | 1 | 5 | 23.892896 | 0.443875 | ops/us | 0 | 256 |
| 13 | shiftLogicalUnsafe | thrpt | 1 | 5 | 20.037400 | 0.197346 | ops/us | 0 | 262 |
| 13 | shiftLogicalUnsafe | thrpt | 1 | 5 | 5.773376 | 0.094510 | ops/us | 0 | 1018 |
| 13 | shiftLogicalUnsafe | thrpt | 1 | 5 | 6.165100 | 0.164495 | ops/us | 0 | 1024 |
| 13 | shiftLogicalUnsafe | thrpt | 1 | 5 | 5.635749 | 0.096095 | ops/us | 0 | 1030 |
| 13 | shiftLogicalUnsafe | thrpt | 1 | 5 | 22.803000 | 2.328542 | ops/us | 1 | 250 |
| 13 | shiftLogicalUnsafe | thrpt | 1 | 5 | 24.306697 | 0.415944 | ops/us | 1 | 256 |
| 13 | shiftLogicalUnsafe | thrpt | 1 | 5 | 19.932682 | 0.397168 | ops/us | 1 | 262 |
| 13 | shiftLogicalUnsafe | thrpt | 1 | 5 | 5.783751 | 0.070052 | ops/us | 1 | 1018 |
| 13 | shiftLogicalUnsafe | thrpt | 1 | 5 | 6.176860 | 0.087320 | ops/us | 1 | 1024 |
| 13 | shiftLogicalUnsafe | thrpt | 1 | 5 | 5.672405 | 0.309824 | ops/us | 1 | 1030 |
| 13 | shiftLogicalUnsafe | thrpt | 1 | 5 | 22.398695 | 6.500715 | ops/us | 7 | 250 |
| 13 | shiftLogicalUnsafe | thrpt | 1 | 5 | 24.016902 | 1.427922 | ops/us | 7 | 256 |
| 13 | shiftLogicalUnsafe | thrpt | 1 | 5 | 19.839427 | 0.253299 | ops/us | 7 | 262 |
| 13 | shiftLogicalUnsafe | thrpt | 1 | 5 | 5.651263 | 0.285734 | ops/us | 7 | 1018 |
| 13 | shiftLogicalUnsafe | thrpt | 1 | 5 | 6.021468 | 0.372450 | ops/us | 7 | 1024 |
| 13 | shiftLogicalUnsafe | thrpt | 1 | 5 | 5.660459 | 0.332135 | ops/us | 7 | 1030 |
| 13 | shiftLogicalUnsafe | thrpt | 1 | 5 | 21.743651 | 0.919695 | ops/us | 8 | 250 |
| 13 | shiftLogicalUnsafe | thrpt | 1 | 5 | 24.134360 | 0.649705 | ops/us | 8 | 256 |
| 13 | shiftLogicalUnsafe | thrpt | 1 | 5 | 19.844468 | 0.083193 | ops/us | 8 | 262 |
| 13 | shiftLogicalUnsafe | thrpt | 1 | 5 | 5.760863 | 0.832170 | ops/us | 8 | 1018 |
| 13 | shiftLogicalUnsafe | thrpt | 1 | 5 | 6.147889 | 0.058199 | ops/us | 8 | 1024 |
| 13 | shiftLogicalUnsafe | thrpt | 1 | 5 | 5.615899 | 0.098102 | ops/us | 8 | 1030 |
This might turn out differently if run on a better machine for benchmarking, won’t be true for AVX-512 chips, and is betting against any benefits from autovectorisation.
What about arithmetic shifts? These preserve the sign, filling with one whenever the most signifcant bit is set, and zero otherwise, and make more sense applied to bytes without masking than unsigned shifts do.
This straightforward code, now targeted for autovectorisation in JDK13, is almost identical:
@Benchmark
public void shiftArithmetic(ByteShiftState state, Blackhole bh) {
byte[] data = state.data;
byte[] target = state.target;
int shift = state.shift;
shiftArithmetic(data, target, shift);
bh.consume(target);
}
void shiftArithmetic(byte[] data, byte[] target, int shift) {
for (int i = 0; i < data.length; ++i) {
target[i] = (byte)(data[i] >> shift);
}
}
It’s very difficult to emulate this 2’s complement operation with SWAR, but it’s possible to do something similar, especially if one considers 0x80 and 0x00 equivalent (for instance, for arithmetic).
First, it is necessary to capture the sign bits (every eighth bit) so they can be preserved.
Then the sign bits must be switched off to stop them from shifting right.
Next, the shift, followed by masking out of any bits shifted into the high bits of each byte.
Finally, the sign bits are reinstated. This doesn’t actually give the correct bitwise result if a byte has been shifted to zero, but is OK for signed arithmetic.
@Benchmark
public void shiftArithmeticUnsafe(ByteShiftState state, Blackhole bh) {
byte[] data = state.data;
byte[] target = state.target;
int shift = state.shift;
shiftArithmeticUnsafe(data, target, shift);
bh.consume(target);
}
void shiftArithmeticUnsafe(byte[] data, byte[] target, int shift) {
long mask = MASKS[shift];
int i = 0;
for (; i + 7 < data.length; i += 8) {
long word = UNSAFE.getLong(data, BYTE_ARRAY_OFFSET + i);
long signs = word & SIGN_BITS;
word &= ~SIGN_BITS;
word >>>= shift;
word &= mask;
word |= signs;
UNSAFE.putLong(target, BYTE_ARRAY_OFFSET + i, word);
}
for (; i < data.length; ++i) {
target[i] = (byte)(data[i] >> shift);
}
}
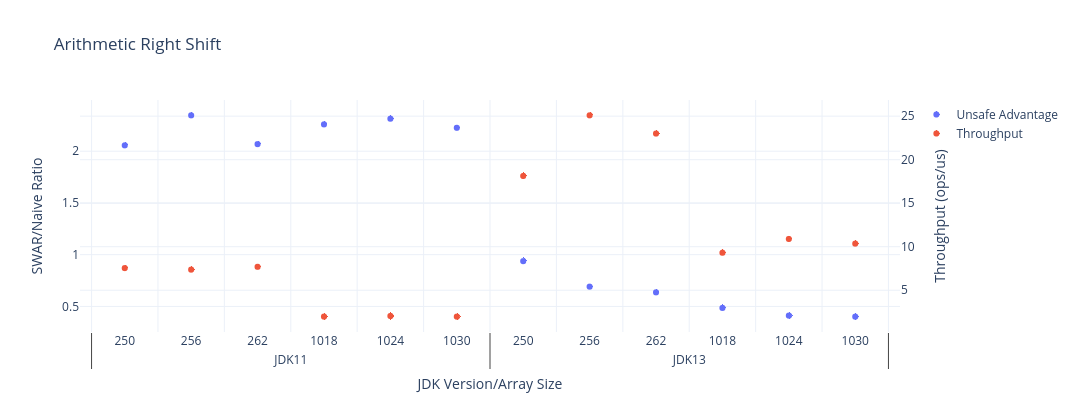
This is a lot more work, which takes its toll on throughput, but is definitely worthwhile in JDK11. Fortunately, there’s no reason to even try (not that I would have, prior to writing this post) because the simple code is faster in JDK13!
Again, the red series below is the measured throughput for each JDK version and array size (the higher the better), and the blue series is the advantage you would get from using Unsafe in each case, with raw data beneath the chart.
Here is a bar chart comparing shiftArithmetic for JDK11 vs JDK13 for the same range of sizes as before.
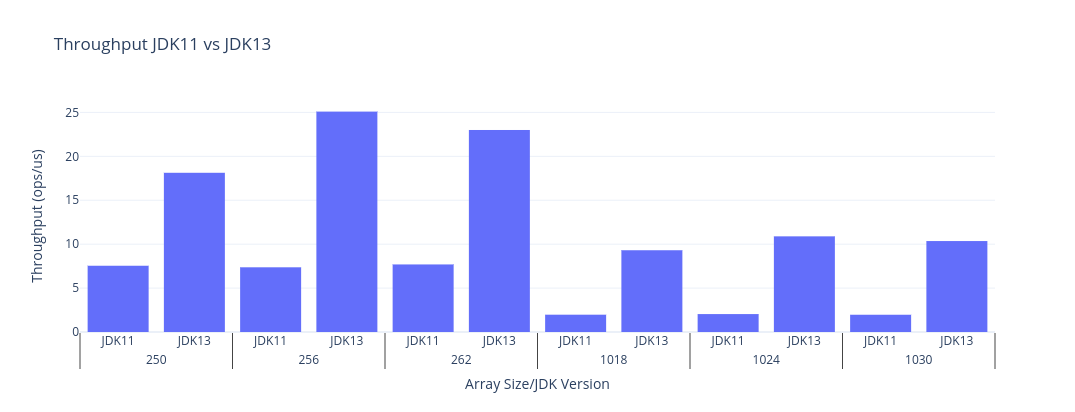
| JDK | Benchmark | Mode | Threads | Samples | Score | Score Error (99.9%) | Unit | Param: shift | Param: size |
|---|---|---|---|---|---|---|---|---|---|
| 11 | shiftArithmetic | thrpt | 1 | 5 | 7.557823 | 0.065235 | ops/us | 0 | 250 |
| 11 | shiftArithmetic | thrpt | 1 | 5 | 7.256637 | 0.981208 | ops/us | 0 | 256 |
| 11 | shiftArithmetic | thrpt | 1 | 5 | 7.476520 | 0.035784 | ops/us | 0 | 262 |
| 11 | shiftArithmetic | thrpt | 1 | 5 | 1.976303 | 0.026156 | ops/us | 0 | 1018 |
| 11 | shiftArithmetic | thrpt | 1 | 5 | 1.958443 | 0.023188 | ops/us | 0 | 1024 |
| 11 | shiftArithmetic | thrpt | 1 | 5 | 1.966061 | 0.026168 | ops/us | 0 | 1030 |
| 11 | shiftArithmetic | thrpt | 1 | 5 | 7.543830 | 0.109140 | ops/us | 1 | 250 |
| 11 | shiftArithmetic | thrpt | 1 | 5 | 7.366226 | 0.046778 | ops/us | 1 | 256 |
| 11 | shiftArithmetic | thrpt | 1 | 5 | 7.691954 | 0.380654 | ops/us | 1 | 262 |
| 11 | shiftArithmetic | thrpt | 1 | 5 | 1.970481 | 0.042620 | ops/us | 1 | 1018 |
| 11 | shiftArithmetic | thrpt | 1 | 5 | 2.039890 | 0.120633 | ops/us | 1 | 1024 |
| 11 | shiftArithmetic | thrpt | 1 | 5 | 1.965348 | 0.010959 | ops/us | 1 | 1030 |
| 11 | shiftArithmetic | thrpt | 1 | 5 | 7.525700 | 0.216891 | ops/us | 7 | 250 |
| 11 | shiftArithmetic | thrpt | 1 | 5 | 7.347915 | 0.071271 | ops/us | 7 | 256 |
| 11 | shiftArithmetic | thrpt | 1 | 5 | 7.488201 | 0.037903 | ops/us | 7 | 262 |
| 11 | shiftArithmetic | thrpt | 1 | 5 | 2.009900 | 0.032639 | ops/us | 7 | 1018 |
| 11 | shiftArithmetic | thrpt | 1 | 5 | 1.958373 | 0.044689 | ops/us | 7 | 1024 |
| 11 | shiftArithmetic | thrpt | 1 | 5 | 2.044459 | 0.216456 | ops/us | 7 | 1030 |
| 11 | shiftArithmetic | thrpt | 1 | 5 | 7.536948 | 0.124611 | ops/us | 8 | 250 |
| 11 | shiftArithmetic | thrpt | 1 | 5 | 7.336482 | 0.059378 | ops/us | 8 | 256 |
| 11 | shiftArithmetic | thrpt | 1 | 5 | 7.470758 | 0.151656 | ops/us | 8 | 262 |
| 11 | shiftArithmetic | thrpt | 1 | 5 | 1.972328 | 0.026727 | ops/us | 8 | 1018 |
| 11 | shiftArithmetic | thrpt | 1 | 5 | 2.027925 | 0.170155 | ops/us | 8 | 1024 |
| 11 | shiftArithmetic | thrpt | 1 | 5 | 1.967295 | 0.025890 | ops/us | 8 | 1030 |
| 13 | shiftArithmetic | thrpt | 1 | 5 | 18.247787 | 0.177523 | ops/us | 0 | 250 |
| 13 | shiftArithmetic | thrpt | 1 | 5 | 25.189287 | 0.083362 | ops/us | 0 | 256 |
| 13 | shiftArithmetic | thrpt | 1 | 5 | 23.878128 | 1.486587 | ops/us | 0 | 262 |
| 13 | shiftArithmetic | thrpt | 1 | 5 | 9.286776 | 0.169307 | ops/us | 0 | 1018 |
| 13 | shiftArithmetic | thrpt | 1 | 5 | 10.914047 | 0.060050 | ops/us | 0 | 1024 |
| 13 | shiftArithmetic | thrpt | 1 | 5 | 10.564764 | 0.303730 | ops/us | 0 | 1030 |
| 13 | shiftArithmetic | thrpt | 1 | 5 | 18.126012 | 0.497112 | ops/us | 1 | 250 |
| 13 | shiftArithmetic | thrpt | 1 | 5 | 25.092744 | 0.685261 | ops/us | 1 | 256 |
| 13 | shiftArithmetic | thrpt | 1 | 5 | 22.999389 | 0.303475 | ops/us | 1 | 262 |
| 13 | shiftArithmetic | thrpt | 1 | 5 | 9.308794 | 0.242943 | ops/us | 1 | 1018 |
| 13 | shiftArithmetic | thrpt | 1 | 5 | 10.889987 | 0.201891 | ops/us | 1 | 1024 |
| 13 | shiftArithmetic | thrpt | 1 | 5 | 10.354830 | 0.204797 | ops/us | 1 | 1030 |
| 13 | shiftArithmetic | thrpt | 1 | 5 | 18.104929 | 0.833391 | ops/us | 7 | 250 |
| 13 | shiftArithmetic | thrpt | 1 | 5 | 25.525225 | 1.058005 | ops/us | 7 | 256 |
| 13 | shiftArithmetic | thrpt | 1 | 5 | 22.890170 | 0.457192 | ops/us | 7 | 262 |
| 13 | shiftArithmetic | thrpt | 1 | 5 | 9.324288 | 0.196076 | ops/us | 7 | 1018 |
| 13 | shiftArithmetic | thrpt | 1 | 5 | 10.891533 | 0.082364 | ops/us | 7 | 1024 |
| 13 | shiftArithmetic | thrpt | 1 | 5 | 10.571187 | 0.222624 | ops/us | 7 | 1030 |
| 13 | shiftArithmetic | thrpt | 1 | 5 | 18.175808 | 0.452371 | ops/us | 8 | 250 |
| 13 | shiftArithmetic | thrpt | 1 | 5 | 25.245452 | 0.396196 | ops/us | 8 | 256 |
| 13 | shiftArithmetic | thrpt | 1 | 5 | 23.109097 | 0.061468 | ops/us | 8 | 262 |
| 13 | shiftArithmetic | thrpt | 1 | 5 | 9.284711 | 0.256823 | ops/us | 8 | 1018 |
| 13 | shiftArithmetic | thrpt | 1 | 5 | 10.877813 | 0.105014 | ops/us | 8 | 1024 |
| 13 | shiftArithmetic | thrpt | 1 | 5 | 10.358305 | 0.292978 | ops/us | 8 | 1030 |
| 13 | shiftArithmeticUnsafe | thrpt | 1 | 5 | 15.628798 | 0.415542 | ops/us | 0 | 250 |
| 13 | shiftArithmeticUnsafe | thrpt | 1 | 5 | 17.272456 | 0.631146 | ops/us | 0 | 256 |
| 13 | shiftArithmeticUnsafe | thrpt | 1 | 5 | 14.438353 | 0.315382 | ops/us | 0 | 262 |
| 13 | shiftArithmeticUnsafe | thrpt | 1 | 5 | 4.415769 | 0.079505 | ops/us | 0 | 1018 |
| 13 | shiftArithmeticUnsafe | thrpt | 1 | 5 | 4.461373 | 0.080921 | ops/us | 0 | 1024 |
| 13 | shiftArithmeticUnsafe | thrpt | 1 | 5 | 4.132034 | 0.250692 | ops/us | 0 | 1030 |
| 13 | shiftArithmeticUnsafe | thrpt | 1 | 5 | 16.992797 | 0.253043 | ops/us | 1 | 250 |
| 13 | shiftArithmeticUnsafe | thrpt | 1 | 5 | 17.342952 | 0.238273 | ops/us | 1 | 256 |
| 13 | shiftArithmeticUnsafe | thrpt | 1 | 5 | 14.627287 | 0.552194 | ops/us | 1 | 262 |
| 13 | shiftArithmeticUnsafe | thrpt | 1 | 5 | 4.517435 | 0.151964 | ops/us | 1 | 1018 |
| 13 | shiftArithmeticUnsafe | thrpt | 1 | 5 | 4.476616 | 0.054379 | ops/us | 1 | 1024 |
| 13 | shiftArithmeticUnsafe | thrpt | 1 | 5 | 4.153728 | 0.068590 | ops/us | 1 | 1030 |
| 13 | shiftArithmeticUnsafe | thrpt | 1 | 5 | 16.935670 | 0.515578 | ops/us | 7 | 250 |
| 13 | shiftArithmeticUnsafe | thrpt | 1 | 5 | 17.668635 | 0.343247 | ops/us | 7 | 256 |
| 13 | shiftArithmeticUnsafe | thrpt | 1 | 5 | 14.408205 | 0.368361 | ops/us | 7 | 262 |
| 13 | shiftArithmeticUnsafe | thrpt | 1 | 5 | 4.436654 | 0.020834 | ops/us | 7 | 1018 |
| 13 | shiftArithmeticUnsafe | thrpt | 1 | 5 | 4.476475 | 0.039526 | ops/us | 7 | 1024 |
| 13 | shiftArithmeticUnsafe | thrpt | 1 | 5 | 4.172609 | 0.061469 | ops/us | 7 | 1030 |
| 13 | shiftArithmeticUnsafe | thrpt | 1 | 5 | 16.987466 | 0.202447 | ops/us | 8 | 250 |
| 13 | shiftArithmeticUnsafe | thrpt | 1 | 5 | 17.403420 | 0.208813 | ops/us | 8 | 256 |
| 13 | shiftArithmeticUnsafe | thrpt | 1 | 5 | 14.464275 | 0.160839 | ops/us | 8 | 262 |
| 13 | shiftArithmeticUnsafe | thrpt | 1 | 5 | 4.443708 | 0.070989 | ops/us | 8 | 1018 |
| 13 | shiftArithmeticUnsafe | thrpt | 1 | 5 | 4.720626 | 0.171716 | ops/us | 8 | 1024 |
| 13 | shiftArithmeticUnsafe | thrpt | 1 | 5 | 4.253040 | 0.088258 | ops/us | 8 | 1030 |
Still, SWAR is an under-utilised technique in Java, and I wish it was possible without using Unsafe, and without forsaking various compiler optimisations.
When I have experimented with the Vector API in Project Panama, the feature I have enjoyed the most is the ability to easily convert between different width integral types.
This is particularly relevant to logical 8-bit right shifts, because they don’t exist in AVX2, and need to be composed from several operations as can be seen in the perfasm output earlier in the post.
AVX2 will become less and less relevant over time, and having access to it on the computer where I play around with this stuff doesn’t make it any more important, but AVX-512 isn’t that widespread yet, and has no support from AMD.
When I last played with the Vector API, I found that having the facility to do SWAR was beneficial for performance when doing a right logical shift in a vector bit count algorithm devised by Wojciech Mula.
Reinterpretation is expressed as a first class concept in the latest version of the API, where the SWAR trick can be seen in shiftRightInt, but not in the more straightforward shiftRightByte. Incidentally, shiftRightByte compiles to similar code to the autovectorised unsigned shift in JDK13.
Of course, it comes at the cost of a loss of generality, but there was a 10x performance difference back in January 2019 between operating on 32 bytes and the faster operation on eight ints.
@Benchmark
public int shiftRightByte() {
return LongVector.fromArray(L256, data, 0)
.reinterpretAsBytes()
.lanewise(LSHR, 4)
.and((byte)0x0F)
.lane(0);
}
@Benchmark
public int shiftRightInt() {
return LongVector.fromArray(L256, data, 0)
.reinterpretAsInts()
.lanewise(LSHR, 4)
.and(0x0F0F0F0F)
.reinterpretAsBytes()
.lane(0);
}
It would be great if there were a general purpose way to do it prior to the potential availability of the Vector API.
My code is at github JDK13 benchmark, Vector API benchmark.