Shrinking BSON Documents
I recently saw a tweet about optimising a DynamoDB instance by shortening attribute names.
#NoSQL databases include both attribute names and values in every item they store. In one design review today we estimated 70% of @DynamoDB IOPS and storage is being consumed by attribute names. Short names will eliminate 14K WCU at peak and reduce table size by 3.5TB. pic.twitter.com/hHN4XIVjWY
— Rick Houlihan (@houlihan_rick) May 12, 2020
The tweet generalised to all NoSQL databases, but when I was asked to reduce the resource requirements of a large MongoDB cluster, I reached the conclusion that the most obvious target - attribute names - wouldn’t lead to the kind of impact I wanted. This post reproduces the analysis I undertook before radically reducing the cost of running that MongoDB cluster. The incentive to reduce document size is for the sake of cache utilisation rather than storage; databases with lots of documents in cache are fast databases, and block level compression algorithms are more effective for storage on disk. I don’t know how much of this applies to DynamoDB.
BSON Specification
If you’re working with a NoSQL database, the data model will be a bit different to a traditional database, making some trade-offs which incur spatial overhead. Understanding the storage format helps to think about ways to reduce the size. Fortunately, BSON, the format MongoDB stores its records in, has a specification so you can find out how large everything you store in your documents is. The Backus-Naur definition below taken from the BSON specification is fairly self-explanatory.
document ::= int32 e_list "\x00" BSON Document. int32 is the total number of bytes comprising the document.
e_list ::= element e_list
| ""
element ::= "\x01" e_name double 64-bit binary floating point
| "\x02" e_name string UTF-8 string
| "\x03" e_name document Embedded document
| "\x04" e_name document Array
| "\x05" e_name binary Binary data
| "\x06" e_name Undefined (value) — Deprecated
| "\x07" e_name (byte*12) ObjectId
| "\x08" e_name "\x00" Boolean "false"
| "\x08" e_name "\x01" Boolean "true"
| "\x09" e_name int64 UTC datetime
| "\x0A" e_name Null value
| "\x0B" e_name cstring cstring Regular expression - The first cstring is the regex pattern, the second is the regex options string. Options are identified by characters, which must be stored in alphabetical order. Valid options are 'i' for case insensitive matching, 'm' for multiline matching, 'x' for verbose mode, 'l' to make \w, \W, etc. locale dependent, 's' for dotall mode ('.' matches everything), and 'u' to make \w, \W, etc. match unicode.
| "\x0C" e_name string (byte*12) DBPointer — Deprecated
| "\x0D" e_name string JavaScript code
| "\x0E" e_name string Symbol. Deprecated
| "\x0F" e_name code_w_s JavaScript code w/ scope
| "\x10" e_name int32 32-bit integer
| "\x11" e_name uint64 Timestamp
| "\x12" e_name int64 64-bit integer
| "\x13" e_name decimal128 128-bit decimal floating point
| "\xFF" e_name Min key
| "\x7F" e_name Max key
e_name ::= cstring Key name
string ::= int32 (byte*) "\x00" String - The int32 is the number bytes in the (byte*) + 1 (for the trailing '\x00'). The (byte*) is zero or more UTF-8 encoded characters.
cstring ::= (byte*) "\x00" Zero or more modified UTF-8 encoded characters followed by '\x00'. The (byte*) MUST NOT contain '\x00', hence it is not full UTF-8.
binary ::= int32 subtype (byte*) Binary - The int32 is the number of bytes in the (byte*).
subtype ::= "\x00" Generic binary subtype
| "\x01" Function
| "\x02" Binary (Old)
| "\x03" UUID (Old)
| "\x04" UUID
| "\x05" MD5
| "\x06" Encrypted BSON value
| "\x80" User defined
code_w_s ::= int32 string document Code w/ scope
Firstly, every element has a type byte, and there are null terminators in all kinds of places. One byte at a time, they add up. Nested documents, of which arrays are a special type, have a four byte length at the start and a null terminator at the end. This means every nested value costs six bytes. There are two kinds of strings: keys, which are null-terminated c-strings, and values, which are length-prefixed, null terminated strings (known as fucked strings). Arrays are documents which means they must have keys. What are those keys? The array index in c-string form (which is useful for MongoDB’s aggregation engine, but you might not have expected it)!
There are a few obvious consequences.
Strings take up less space if they can be modeled as keys; eliminating nesting reduces as much space as renaming metrics to m.
BSON Analyser
The best way I found to experiment with schema changes is to encode the information about BSON element sizes into a tool which can parse BSON.
MongoDB’s Java driver’s BsonWriter is easy to implement and easy to compose with a BSON reader.
I implemented BsonWriter to update counters during document parsing.
A BSON or JSON extract can be fed in to the overhead analyser to get a break down of size by document feature.
This makes it easy to tweak a document slightly, and see what impact the change made.
Metrics Example
I followed the process below on a past project, with a data model I can’t mention the details of, but replicate it here with a made up data model. The example documents contain metrics taken by sensors. Each step preserves all relationships within the document but makes trade-offs, and it really depends on the application whether they are worth it, but each step also creates a budget for additional features in the documents. If you reduce the size of a document by 1KB, increasing its size by 200 bytes for easier indexing comes for better than free.
Baseline
Here’s the starting point, a document which contains a snapshot of 3 metrics with different percentiles (the JSON gets shorter if you keep going).
{
"id": "1000000000000",
"metrics": [
{
"tags": [ "tag1","tag2", "tag3" ],
"percentile": "p50",
"metric": "metric1",
"timestamp": 1029831028310928,
"value": 1029831.102938
},
{
"tags": [ "tag1", "tag2", "tag3" ],
"percentile": "p90",
"metric": "metric1",
"timestamp": 1029831028310928,
"value": 1129831.102938
},
{
"tags": [ "tag1", "tag2", "tag3" ],
"percentile": "p95",
"metric": "metric1",
"timestamp": 1029831028310928,
"value": 1129831.102938
},
{
"tags": [ "tag1", "tag2", "tag3" ],
"percentile": "p99",
"metric": "metric1",
"timestamp": 1029831028310928,
"value": 1229831.102938
},
{
"tags": [ "tag1", "tag3", "tag4" ],
"percentile": "p50",
"metric": "metric2",
"timestamp": 1029831028310928,
"value": 1029831.102938
},
{
"tags": [ "tag1", "tag3", "tag4" ],
"percentile": "p90",
"metric": "metric2",
"timestamp": 1029831028310928,
"value": 1129831.102938
},
{
"tags": [ "tag1", "tag3", "tag4" ],
"percentile": "p95",
"metric": "metric2",
"timestamp": 1029831028310928,
"value": 1129831.102938
},
{
"tags": [ "tag1", "tag3", "tag4" ],
"percentile": "p99",
"metric": "metric2",
"timestamp": 1029831028310928,
"value": 1229831.102938
},
{
"tags": [ "tag1", "tag2" ],
"percentile": "p50",
"metric": "metric3",
"timestamp": 1029831028310928,
"value": 1029831.102938
},
{
"tags": [ "tag1", "tag2" ],
"percentile": "p90",
"metric": "metric3",
"timestamp": 1029831028310928,
"value": 1129831.102938
},
{
"tags": [ "tag1", "tag2" ],
"percentile": "p95",
"metric": "metric3",
"timestamp": 1029831028310928,
"value": 1129831.102938
},
{
"tags": [ "tag1", "tag2" ],
"percentile": "p99",
"metric": "metric3",
"timestamp": 1029831028310928,
"value": 1229831.102938
}
]
}
When converted to BSON, this document is fairly large: 1.5KB with over 50% overhead.
raw.json
+----------------------------------------------+
data size by type (total): 738B
DOUBLE: 96B
STRING: 546B
INT64: 96B
binary type markers (total): 0B
+----------------------------------------------+
attribute (total): 463B
null terminators: 189B
+----------------------------------------------+
document lengths (total): 104B
metrics: 52B
root: 4B
tags: 48B
+----------------------------------------------+
data (total): 738B
id: 18B
metric: 144B
percentile: 96B
tags: 288B
timestamp: 96B
value: 96B
-------------------------------------------+
DOUBLE: 96B
STRING: 546B
INT64: 96B
+----------------------------------------------+
document size (total): 1543B
Overhead: 52.17%
Shrinking Attributes
Let’s chase the biggest item in the profile (this is what you’re supposed to do, right?) and replace the attribute names with single characters. This saves over 300 bytes. Not bad.
raw-minified.json
+----------------------------------------------+
data size by type (total): 747B
DOUBLE: 96B
STRING: 555B
INT64: 96B
binary type markers (total): 0B
+----------------------------------------------+
attribute (total): 109B
null terminators: 191B
+----------------------------------------------+
document lengths (total): 104B
b: 52B
c: 48B
root: 4B
+----------------------------------------------+
data (total): 747B
a: 18B
c: 297B
d: 96B
e: 144B
f: 96B
g: 96B
-------------------------------------------+
DOUBLE: 96B
STRING: 555B
INT64: 96B
+----------------------------------------------+
document size (total): 1200B
Overhead: 37.75%
If you’ve ever set up indexes on a database, this will horrify you, so it’s worth avoiding doing this.
Normalisation
There’s some duplication in the document: the timestamp can be moved up to the root level, and the obviously numeric identifier is a string.
Changing the identifier to an int64 will save a little bit of space, but if it ends up in an index, will speed up queries a lot for various reasons.
It might not be possible to change the data type, but if you’re not in control of it, it’s likely you can have a conversation with someone who is, and might be coercible if they can be convinced they stand to gain from the change.
{
"id": 1000000000000,
"timestamp": 1029831028310928,
"metrics": [
{
"tags": [ "tag1", "tag2", "tag3" ],
"percentile": "p50",
"metric": "metric1",
"value": 1029831.102938
},
{
"tags": [ "tag1", "tag2", "tag3" ],
"percentile": "p90",
"metric": "metric1",
"value": 1129831.102938
},
{
"tags": [ "tag1", "tag2", "tag3" ],
"percentile": "p95",
"metric": "metric1",
"value": 1129831.102938
},
{
"tags": [ "tag1", "tag2", "tag3" ],
"percentile": "p99",
"metric": "metric1",
"value": 1229831.102938
},
{
"tags": [ "tag1", "tag3", "tag4" ],
"percentile": "p50",
"metric": "metric2",
"value": 1029831.102938
},
{
"tags": [ "tag1", "tag3", "tag4" ],
"percentile": "p90",
"metric": "metric2",
"value": 1129831.102938
},
{
"tags": [ "tag1", "tag3", "tag4" ],
"percentile": "p95",
"metric": "metric2",
"value": 1129831.102938
},
{
"tags": [ "tag1", "tag3", "tag4" ],
"percentile": "p99",
"metric": "metric2",
"value": 1229831.102938
},
{
"tags": [ "tag1", "tag2" ],
"percentile": "p50",
"metric": "metric3",
"value": 1029831.102938
},
{
"tags": [ "tag1", "tag2" ],
"percentile": "p90",
"metric": "metric3",
"value": 1129831.102938
},
{
"tags": [ "tag1", "tag2" ],
"percentile": "p95",
"metric": "metric3",
"value": 1129831.102938
},
{
"tags": [ "tag1", "tag2" ],
"percentile": "p99",
"metric": "metric3",
"value": 1229831.102938
}
]
}
Just normalising the document and using the right data type gets close to minifying the attributes.
normalised.json
+----------------------------------------------+
data size by type (total): 640B
DOUBLE: 96B
STRING: 528B
INT64: 16B
binary type markers (total): 0B
+----------------------------------------------+
attribute (total): 364B
null terminators: 177B
+----------------------------------------------+
document lengths (total): 104B
metrics: 52B
root: 4B
tags: 48B
+----------------------------------------------+
data (total): 640B
id: 8B
metric: 144B
percentile: 96B
tags: 288B
timestamp: 8B
value: 96B
-------------------------------------------+
DOUBLE: 96B
STRING: 528B
INT64: 16B
+----------------------------------------------+
document size (total): 1324B
Overhead: 51.66%
Inverted Tags Index
Denormalising the timestamps may have been a little contrived, but removing duplication from the document is a good strategy.
Next is the tags: there’s a lot of repetition and strings take up less space as keys than values.
Why not add a sub document with an inverted index by tag over the metrics?
Below, $.index.tag1 contains all the indices into $.metrics which have "tag1".
{
"id": 1000000000000,
"timestamp": 1029831028310928,
"index": {
"tag1": [ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11 ],
"tag2": [ 0, 1, 2, 3, 8, 9, 10, 11 ],
"tag3": [ 0, 1, 2, 3, 4, 5, 6, 7 ],
"tag4": [ 4, 5, 6, 7 ]
},
"metrics": [
{
"percentile": "p50",
"metric": "metric1",
"value": 1029831.102938
},
{
"percentile": "p90",
"metric": "metric1",
"value": 1129831.102938
},
{
"percentile": "p95",
"metric": "metric1",
"value": 1129831.102938
},
{
"percentile": "p99",
"metric": "metric1",
"value": 1229831.102938
},
{
"percentile": "p50",
"metric": "metric2",
"value": 1029831.102938
},
{
"percentile": "p90",
"metric": "metric2",
"value": 1129831.102938
},
{
"percentile": "p95",
"metric": "metric2",
"value": 1129831.102938
},
{
"percentile": "p99",
"metric": "metric2",
"value": 1229831.102938
},
{
"percentile": "p50",
"metric": "metric3",
"value": 1029831.102938
},
{
"percentile": "p90",
"metric": "metric3",
"value": 1129831.102938
},
{
"percentile": "p95",
"metric": "metric3",
"value": 1129831.102938
},
{
"percentile": "p99",
"metric": "metric3",
"value": 1229831.102938
}
]
}
This sheds another 300B, and makes sense unless you want to index by tag; it rearranges the document so that an application could interpret the document structure. As data is moved from the values to the keys, the overhead percentage starts to make less sense; it increases in this step.
indexed.json
+----------------------------------------------+
data size by type (total): 480B
DOUBLE: 96B
STRING: 240B
INT32: 128B
INT64: 16B
binary type markers (total): 0B
+----------------------------------------------+
attribute (total): 339B
null terminators: 131B
+----------------------------------------------+
document lengths (total): 76B
index: 4B
metrics: 52B
root: 4B
tag1: 4B
tag2: 4B
tag3: 4B
tag4: 4B
+----------------------------------------------+
data (total): 480B
id: 8B
metric: 144B
percentile: 96B
tag1: 48B
tag2: 32B
tag3: 32B
tag4: 16B
timestamp: 8B
value: 96B
-------------------------------------------+
DOUBLE: 96B
STRING: 240B
INT32: 128B
INT64: 16B
+----------------------------------------------+
document size (total): 1090B
Overhead: 55.96%
Binary Tag Format
BSON arrays aren’t as dense as they look, so the arrays could be replaced by bitsets in binary format.
{
"id": 1000000000000,
"timestamp": 1029831028310928,
"index": {
"tag1": { "$binary": "AAA=", "$type": "00" },
"tag2": { "$binary": "AAA=", "$type": "00" },
"tag3": { "$binary": "AA==", "$type": "00" },
"tag4": { "$binary": "AA==", "$type": "00" }
},
"metrics": [
{
"percentile": "p50",
"metric": "metric1",
"value": 1029831.102938
},
{
"percentile": "p90",
"metric": "metric1",
"value": 1129831.102938
},
{
"percentile": "p95",
"metric": "metric1",
"value": 1129831.102938
},
{
"percentile": "p99",
"metric": "metric1",
"value": 1229831.102938
},
{
"percentile": "p50",
"metric": "metric2",
"value": 1029831.102938
},
{
"percentile": "p90",
"metric": "metric2",
"value": 1129831.102938
},
{
"percentile": "p95",
"metric": "metric2",
"value": 1129831.102938
},
{
"percentile": "p99",
"metric": "metric2",
"value": 1229831.102938
},
{
"percentile": "p50",
"metric": "metric3",
"value": 1029831.102938
},
{
"percentile": "p90",
"metric": "metric3",
"value": 1129831.102938
},
{
"percentile": "p95",
"metric": "metric3",
"value": 1129831.102938
},
{
"percentile": "p99",
"metric": "metric3",
"value": 1229831.102938
}
]
}
This saves another 200B, but absolutely rules out indexing on tag.
indexed-bitset.json
+----------------------------------------------+
data size by type (total): 374B
DOUBLE: 96B
STRING: 240B
BINARY: 22B
INT64: 16B
binary type markers (total): 4B
+----------------------------------------------+
attribute (total): 305B
null terminators: 95B
+----------------------------------------------+
document lengths (total): 60B
index: 4B
metrics: 52B
root: 4B
+----------------------------------------------+
data (total): 374B
id: 8B
metric: 144B
percentile: 96B
tag1: 6B
tag2: 6B
tag3: 5B
tag4: 5B
timestamp: 8B
value: 96B
-------------------------------------------+
DOUBLE: 96B
STRING: 240B
BINARY: 22B
INT64: 16B
+----------------------------------------------+
document size (total): 870B
Overhead: 57.01%
Factorisation
The percentile names and metric names are repeated a lot.
This duplication can be removed by thinking of the metrics as a matrix, with percentile on the columns and metric on the rows.
The values are ordered by metric and then percentile.
To get the value for ("metric1", "p50"), get the zero based position of "metric1" within the metrics, m, and the zero based position of "p50" within the positions, p.
The value is at index m * 4 + p.
This is possible because the association between tags and metrics is no longer represented by an embedding, and because there is an application collaborating with the database on schema management.
{
"id": 1000000000000,
"timestamp": 1029831028310928,
"index": {
"tag1": { "$binary": "AAA=", "$type": "00" },
"tag2": { "$binary": "AAA=", "$type": "00" },
"tag3": { "$binary": "AA==", "$type": "00" },
"tag4": { "$binary": "AA==", "$type": "00" }
},
"percentiles": [ "p50", "p90", "p95", "p99" ],
"metrics": [ "metric1", "metric2", "metric3" ],
"values": [
1029831.102938, 1129831.102938, 1129831.102938, 1229831.102938, 1029831.102938, 1129831.102938, 1129831.102938, 1229831.102938, 1029831.102938, 1129831.102938, 1129831.102938, 1229831.102938
]
}
This gets below 400B, more than 1KB of space has been saved.
matrix.json
+----------------------------------------------+
data size by type (total): 202B
DOUBLE: 96B
STRING: 68B
BINARY: 22B
INT64: 16B
binary type markers (total): 4B
+----------------------------------------------+
attribute (total): 77B
null terminators: 41B
+----------------------------------------------+
document lengths (total): 20B
index: 4B
metrics: 4B
percentiles: 4B
root: 4B
values: 4B
+----------------------------------------------+
data (total): 202B
id: 8B
metrics: 36B
percentiles: 32B
tag1: 6B
tag2: 6B
tag3: 5B
tag4: 5B
timestamp: 8B
values: 96B
-------------------------------------------+
DOUBLE: 96B
STRING: 68B
BINARY: 22B
INT64: 16B
+----------------------------------------------+
document size (total): 366B
Overhead: 44.81%
Binary Values Array
Again, arrays aren’t as dense as they look, it’s unlikely the values need to be indexed, and binary values are easy to unpack in the application layer.
{
"id": 1000000000000,
"timestamp": 1029831028310928,
"index": {
"tag1": { "$binary": "AAA=", "$type": "00" },
"tag2": { "$binary": "AAA=", "$type": "00" },
"tag3": { "$binary": "AA==", "$type": "00" },
"tag4": { "$binary": "AA==", "$type": "00" }
},
"percentiles": [ "p50", "p90", "p95", "p99" ],
"metrics": [ "metric1", "metric2", "metric3" ],
"values": {"$binary": "QS9tjjS0Sh9BMT1nGlolEEExPWcaWiUQQTLEBxpaJRBBL22ONLRKH0ExPWcaWiUQQTE9ZxpaJRBBMsQHGlolEEEvbY40tEofQTE9ZxpaJRBBMT1nGlolEEEyxAcaWiUQ", "$type": "00"}
}
This is getting in to scraping the barrel territory, and only a further 40B is saved:
binary.json
+----------------------------------------------+
data size by type (total): 206B
STRING: 68B
BINARY: 122B
INT64: 16B
binary type markers (total): 5B
+----------------------------------------------+
attribute (total): 63B
null terminators: 28B
+----------------------------------------------+
document lengths (total): 16B
index: 4B
metrics: 4B
percentiles: 4B
root: 4B
+----------------------------------------------+
data (total): 206B
id: 8B
metrics: 36B
percentiles: 32B
tag1: 6B
tag2: 6B
tag3: 5B
tag4: 5B
timestamp: 8B
values: 100B
-------------------------------------------+
STRING: 68B
BINARY: 122B
INT64: 16B
+----------------------------------------------+
document size (total): 328B
Overhead: 37.20%
Shrinking Remaining Attributes
Finally, it’s true, document database do like short attribute names, but you need to be able to write index configuration too. The names can be shortened, but not further than would make database configuration painful.
{
"id": 1000000000000,
"ts": 1029831028310928,
"idx": {
"tag1": { "$binary": "AAA=", "$type": "00" },
"tag2": { "$binary": "AAA=", "$type": "00" },
"tag3": { "$binary": "AA==", "$type": "00" },
"tag4": { "$binary": "AA==", "$type": "00" }
},
"pctl": [ "p50", "p90", "p95", "p99" ],
"name": [ "metric1", "metric2", "metric3"],
"v": {"$binary": "QS9tjjS0Sh9BMT1nGlolEEExPWcaWiUQQTLEBxpaJRBBL22ONLRKH0ExPWcaWiUQQTE9ZxpaJRBBMsQHGlolEEEvbY40tEofQTE9ZxpaJRBBMT1nGlolEEEyxAcaWiUQ", "$type": "00"}
}
This saves another 25B.
minimised.json
+----------------------------------------------+
data size by type (total): 206B
STRING: 68B
BINARY: 122B
INT64: 16B
binary type markers (total): 5B
+----------------------------------------------+
attribute (total): 39B
null terminators: 28B
+----------------------------------------------+
document lengths (total): 16B
idx: 4B
name: 4B
pctl: 4B
root: 4B
+----------------------------------------------+
data (total): 206B
id: 8B
name: 36B
pctl: 32B
tag1: 6B
tag2: 6B
tag3: 5B
tag4: 5B
ts: 8B
v: 100B
-------------------------------------------+
STRING: 68B
BINARY: 122B
INT64: 16B
+----------------------------------------------+
document size (total): 304B
Overhead: 32.24%
Improvements Create Feature Budget
The improvements can be summarised with a bar chart, sorted by document size, with shrinking the attribute names towards the left.
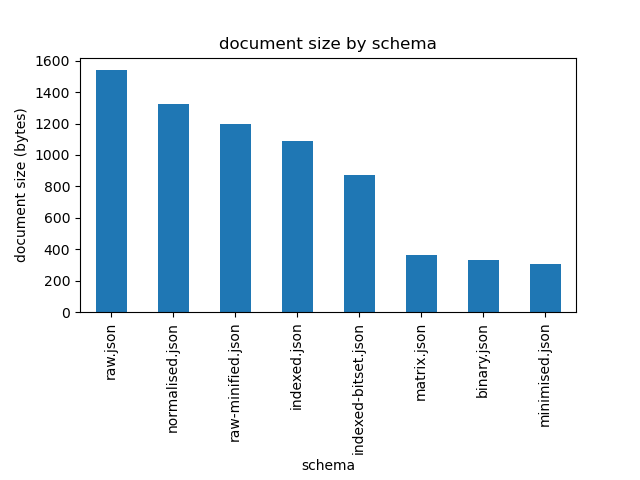
MongoDB experts might be screaming at this point: it’s impossible to index the the documents by tag, for instance. If that’s a requirement, more than enough budget has been created to add a set of tags at the root level of the document by now, but shrinking the attribute names would not have got close to justifying adding more duplication for the sake of indexing.