Finding Bytes in Arrays
Thanks to everybody who reviewed and made helpful suggestions to improve this post.
This post considers the benefits of branch-free algorithms through the lens of a trivial problem: finding the first position of a byte within an array.
While this problem is simple, it has many applications in parsing:
BSON keys are null terminated strings;
HTTP 1.1 headers are delimited by CRLF sequences;
CBOR arrays are terminated by the stop character 0xFF.
I compare the most obvious, but branchy, implementation with a branch-free implementation, and use the Vector API in Project Panama to improve performance.
- Motivation: Parsing BSON
- Finding Null Terminators without Branches
- Microbenchmarks
- Searching for Arbitrary Bytes
- Artificially Narrow Pipes
- Vectorisation?
- Conclusions
Motivation: Parsing BSON
BSON has a very simple structure: except at the very top level, it is a list of triplets consisting of a type byte, a name, and a (recursively defined) BSON value. To write a BSON parser, you just need a jump table associating each value type with a parser. As you scan the input, you read the type byte, read the attribute name, then look up and invoke the parser for the current type.
Flexibility comes at a price: the attribute names in documents represent significant overhead compared to relational database tuples. To save space, attribute names in BSON are null terminated, at the cost of one byte, rather than length-prefixed which would cost four. This means that extracting the name is linear in its length, rather than constant time. Here’s what this looks like in the MongoDB Java driver:
@Override
public String readCString() {
ensureOpen();
// TODO: potentially optimize this
int mark = buffer.position();
readUntilNullByte();
int size = buffer.position() - mark;
buffer.position(mark);
return readString(size);
}
private void readUntilNullByte() {
//CHECKSTYLE:OFF
while (readByte() != 0) { //NOPMD
//do nothing - checkstyle & PMD hate this, not surprisingly
}
//CHECKSTYLE:ON
}
If you find yourself with a very large MongoDB cluster and are sensible, you will quickly make three document schema changes:
- Replace the attribute names with very short codes.
- Reduce nesting! BSON trivia: each document has a 4 byte length marker, and they accumulate quickly.
- Use arrays where possible.
If you can make all of these changes, you will have a larger impact on throughput than optimising the BSON parser.
I recently worked on a project which couldn’t make these changes, so I wrote a proprietary BSON parser much faster than the MongoDB Java driver implementation.
You won’t get too far just by reimplementing readUntilNullByte, but it’s a good start. Without making all of the schema changes your documents will contain lots of variable length names, and will therefore hit many unpredictable branches while traversing documents.
Finding Null Terminators without Branches
How do you extract null terminated strings without branching? Fortunately, it’s a very old problem and Chapter 6 of Hacker’s Delight has a solution to find a zero byte in a 32 bit word, which can be adapted to process 64 bits at a time. The code looks weird though.
private static int firstZeroByte(long word) {
long tmp = (word & 0x7F7F7F7F7F7F7F7FL) + 0x7F7F7F7F7F7F7F7FL;
tmp = ~(tmp | word | 0x7F7F7F7F7F7F7F7FL);
return Long.numberOfLeadingZeros(tmp) >>> 3;
}
Explaining this to myself as if to a five year old was helpful.
The mask 0x7F masks out the eighth bit of a byte, which creates a “hole” for a bit to carry into.
Adding 0x7F to the masked value will cause a carry over into the hole if and only if any of the lower seven bits are set.
Now, the value 0x7F in tmp indicates that the input was either 0x0 or 0x80, and if the byte is negated, we get 0x80.
Any other input value will have the eighth bit set, so the complement of its union with 0x7F makes 0x0.
In order to knock out any 0x80s present in the input, the input word is included in the union because ~(0x80 | 0x7F) is zero.
After performing the negated union, wherever the input byte was zero, the eighth bit will be set.
Taking the number of leading zeroes (a hotspot intrinsic targeting the lzcnt/clz instructions) gives the position of the bit.
Dividing by eight gives the position of the byte.
Some (big-endian) examples might help:
If the bytes are all zero, the index of the first zero byte should be zero.
// all zeroes
private static int firstZeroByte(long word) {
// word = 0b0000000000000000000000000000000000000000000000000000000000000000
long tmp = (word & 0x7F7F7F7F7F7F7F7FL) + 0x7F7F7F7F7F7F7F7FL;
// tmp = 0b0111111101111111011111110111111101111111011111110111111101111111
tmp = ~(tmp | word | 0x7F7F7F7F7F7F7F7FL);
// tmp = 0b1000000010000000100000001000000010000000100000001000000010000000
return Long.numberOfLeadingZeros(tmp) >>> 3; // 0 / 8 = 0
}
If the bytes are all 0x80, the index of the first zero byte should be indicate that no zero byte was found.
// all 0x80
private static int firstZeroByte(long word) {
// word = 0b1000000010000000100000001000000010000000100000001000000010000000
long tmp = (word & 0x7F7F7F7F7F7F7F7FL) + 0x7F7F7F7F7F7F7F7FL;
// tmp = 0b0111111101111111011111110111111101111111011111110111111101111111
tmp = ~(tmp | word | 0x7F7F7F7F7F7F7F7FL);
// tmp = 0b0000000000000000000000000000000000000000000000000000000000000000
return Long.numberOfLeadingZeros(tmp) >>> 3; // 64 / 8 = 8 (not found)
}
For the sequence of bytes below, we should find a zero at index 5.
// {31, 25, 100, 0x7F, 9, 0, 127, 0x80}
private static int firstZeroByte(long word) {
// word = 0b0001111100011001011001000111111100001001000000000111111110000000
long tmp = (word & 0x7F7F7F7F7F7F7F7FL) + 0x7F7F7F7F7F7F7F7FL;
// tmp = 0b1001111010011000111000111111111010001000011111111111111001111111
tmp = ~(tmp | word | 0x7F7F7F7F7F7F7F7FL);
// tmp = 0b0000000000000000000000000000000000000000100000000000000000000000
return Long.numberOfLeadingZeros(tmp) >>> 3; // 40 / 8 = 5
}
Microbenchmarks
I like to find some evidence in favour of a change in idealised settings before committing to prototyping the change. Though effects are often more pronounced in microbenchmarks than at system level, if I can’t find evidence of improvement in conditions which I can easily control, I wouldn’t want to waste time hacking the change into existing code. Contrary to widespread prejudice against microbenchmarking, I find a lot of bad ideas can be killed off quickly by spending a little bit of time doing bottom-up benchmark experiments.
Despite that, it’s very easy to write a microbenchmark to discard the branch-free implementation by creating very predictable benchmark data, and it’s very common not to vary microbenchmark data much to avoid garbage collection related noise. The problem with making this comparison is that branch prediction is both effective and stateful on modern processors. The branch predictor is capable of learning the branch decisions implied by the benchmark data; the benchmark must be able to maintain uncertainty without introducing other confounding factors.
Dan Luu’s presentation about branch predictors is excellent.
While the BSON attribute extraction use case is focused on very small strings, I also vary the length of the strings from very small to large, with the null terminator at a random position within the last eight bytes of the input. To make the data unpredictable without creating GC noise, I generate lots of similar inputs and cycle through them on each invocation. I want the cycling to be almost free so choose parameterised powers of two to vary the number of inputs.
When there aren’t many inputs, the branchy version should be faster and the number of perf branch-misses should be low, and should slow down as more distinct inputs are provided.
That is, I expect the branch predictor to learn the benchmark data when too few distinct inputs are provided.
I expect the branch-free version to be unaffected by the variability of the input.
I called the branchy implementation “scan” and the branch-free implementation “swar” (for SIMD Within A Register).
Focusing only on the smaller inputs relevant to BSON parsing (where the null terminator is found somewhere in the first eight bytes), it’s almost as if I ran the benchmarks before making the predictions.
The benchmark was run on OpenJDK 13 on Ubuntu 18.04.3 LTS, on a i7-6700HQ CPU.
| inputs | scan:branch-misses | scan:CPI | scan (ops/us) | swar (ops/us) | swar:CPI | swar:branch-misses |
|---|---|---|---|---|---|---|
| 128 | 0.00 | 0.24 | 210.94 | 205.42 | 0.26 | 0.00 |
| 256 | 0.00 | 0.24 | 210.53 | 205.00 | 0.26 | 0.00 |
| 512 | 0.00 | 0.25 | 208.37 | 205.33 | 0.26 | 0.00 |
| 1024 | 0.05 | 0.40 | 129.23 | 201.10 | 0.26 | 0.00 |
| 2048 | 0.50 | 0.55 | 91.41 | 204.32 | 0.27 | 0.00 |
| 4096 | 0.80 | 0.70 | 72.50 | 204.62 | 0.26 | 0.00 |
| 8192 | 0.90 | 0.75 | 67.31 | 204.60 | 0.26 | 0.00 |
| 16384 | 0.98 | 0.79 | 63.83 | 204.28 | 0.26 | 0.00 |
| 32768 | 0.98 | 0.80 | 62.13 | 204.26 | 0.26 | 0.00 |
The far left column is the number of distinct inputs fed to the benchmark. The inner two columns are the throughputs in operations per microsecond; the branchy implementation (scan) reducing as a function of input variety; the branch-free implementation (swar) constant. Cycles per instruction (CPI) is constant for the branch-free implementation; the percentage of branches missed is noisy but stationary. As input variety is increased, branch misses climb from 0 (the input has been learnt) to 0.98 per invocation, with CPI increasing roughly in proportion. The branch-free implementation would have seemed like a really bad idea with just one random input.
The best way I could think to visualise this result was as a bar chart grouping measurements by size. While the scan measurements are highly sensitive to the number of inputs, the swar measurements are insensitive to variety until the sizes are large enough to hit other limits.
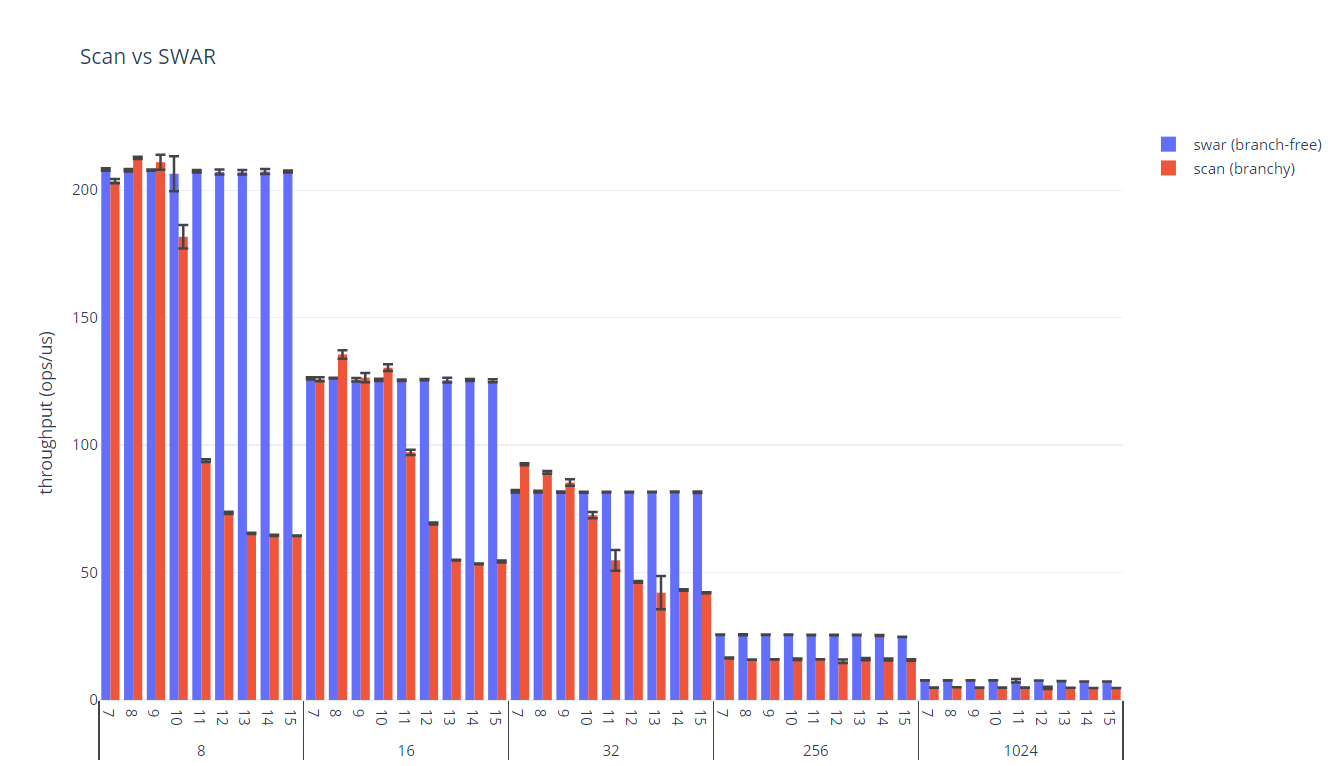
Searching for Arbitrary Bytes
Arbitrary bytes can be found by, in effect, modifying the input such that a search for a zero byte would produce the correct answer. This can be done cheaply by XORing the input with the broadcast word of the sought byte. For instance, line-feeds can be found:
int position = firstInstance(getWord(new byte[]{1, 2, 0, 3, 4, 10, (byte)'\n', 5}, 0), compilePattern((byte)'\n');
...
private static long compilePattern(byte byteToFind) {
long pattern = byteToFind & 0xFFL;
return pattern
| (pattern << 8)
| (pattern << 16)
| (pattern << 24)
| (pattern << 32)
| (pattern << 40)
| (pattern << 48)
| (pattern << 56);
}
private static int firstInstance(long word, long pattern) {
long input = word ^ pattern;
long tmp = (input & 0x7F7F7F7F7F7F7F7FL) + 0x7F7F7F7F7F7F7F7FL;
tmp = ~(tmp | input | 0x7F7F7F7F7F7F7F7FL);
return Long.numberOfLeadingZeros(tmp) >>> 3;
}
Artificially Narrow Pipes
One of the benefits in working 64 bits at a time is reducing the number of load instructions required to scan the input. This corroborates with the normalised instruction counts from the benchmark data (slicing on the 128 inputs case because it doesn’t make any difference):
| input size | 8 | 16 | 32 | 256 | 1024 |
|---|---|---|---|---|---|
| scan:instructions | 67.58 | 104.47 | 161.83 | 957.62 | 3575.40 |
| swar:instructions | 65.23 | 101.78 | 138.01 | 532.02 | 1838.21 |
There are various places in Netty, a popular networking library, where line feeds and various other bytes are searched for in buffers. For example, here is how Netty searches for line feeds, which avoids bounds checks, but prevents the callback from being able to operate on several bytes at a time.
/**
* A {@link ByteProcessor} which finds the first appearance of a specific byte.
*/
class IndexOfProcessor implements ByteProcessor {
private final byte byteToFind;
public IndexOfProcessor(byte byteToFind) {
this.byteToFind = byteToFind;
}
@Override
public boolean process(byte value) {
return value != byteToFind;
}
}
/**
* Aborts on a {@code LF ('\n')}.
*/
ByteProcessor FIND_LF = new IndexOfProcessor(LINE_FEED);
This seems like such a narrow conduit to pipe data through, and maximum efficiency is precluded by abstraction here.
Ultimately, we have APIs like this in Java because people (rightly) don’t want to copy data, but the language lacks const semantics.
Hiding data and funneling it through narrow pipes prevents saturation of the hardware, and only much smarter JIT compilation (better inlining, better at spotting and rewriting idioms) could compensate for this.
Narrow cross-boundary data transfer will limit opportunities to exploit explicit vectorisation when it becomes available.
Vectorisation?
The branch-free algorithm is scalable in that it can mark bytes (that is, set interesting bytes to 0x80) in as wide a word as you like.
With AVX-512 this means processing 64 bytes in parallel, which could be quite effective for large inputs.
Finding the leftmost tagged bit does not have a straightforward vector analogue, because there’s no built-in way of extracting the number of leading zeroes of the entire vector.
However, whenever there is no match, a zero vector will be produced, which can be tested.
When a non-zero vector is produced, the scalar values can be extracted and Long.numberOfLeadingZeros can be used to get the position of the tag bit.
This isn’t branch-free, but it reduces the number of branches by a factor of the vector width.
This is the implementation based on a recent build of the vectorIntrinsics branch of the Vector API.
public static int firstZeroByte(byte[] data) {
// underflow
if (data.length < B256.length()) {
return firstNonZeroByteSWAR(data);
}
int offset = 0;
int loopBound = B256.loopBound(data.length);
var holes = ByteVector.broadcast(B256, (byte)0x7F);
var zero = ByteVector.zero(B256);
while (offset < loopBound) {
var vector = ByteVector.fromArray(B256, data, offset);
var tmp = vector.and(holes).add(holes).or(vector).or(holes).not();
if (!tmp.eq(zero).allTrue()) {
var longs = vector.reinterpretAsLongs();
for (int i = 0; i < L256.length(); ++i) {
long word = longs.lane(i);
if (word != 0) {
return offset + B256.length() - (i * Long.BYTES + Long.numberOfLeadingZeros(word) >>> 3);
}
}
}
offset += B256.length();
}
// post loop
if (loopBound != data.length) {
var vector = ByteVector.fromArray(B256, data, data.length - B256.length());
var tmp = vector.and(holes).add(holes).or(vector).or(holes).not();
if (!tmp.eq(zero).allTrue()) {
var longs = vector.reinterpretAsLongs();
for (int i = 0; i < L256.length(); ++i) {
long word = longs.lane(i);
if (word != 0) {
return offset + B256.length() - (i * Long.BYTES + Long.numberOfLeadingZeros(word) >>> 3);
}
}
}
}
return -1;
}
This implementation is much faster than either scalar version, but the performance depends on the choice of vector type and the hardware.
Any of ByteVector, IntVector, and LongVector could have been used, but ByteVector works best on most platforms.
Choosing LongVector and running on sub AVX-512 hardware would mean there would be no supported intrinsic for the addition at runtime and the API would need to default to a scalar implementation.
This fallback isn’t that bad at the moment, probably slightly slower than scalar code, whereas when I first tried using this API last year it could easily be over 100x slower.
The numbers below, for 1KB byte[]s, are not directly comparable to the numbers above because they were run with a custom built JDK, but give an idea of the possible improvement in throughput.
The benchmark was run using a JDK built from the vectorIntrinsics on Ubuntu 18.04.3 LTS, on a i7-6700HQ CPU.
| inputs | scan:LLC-load-misses | scan:branch-misses | scan:CPI | scan (ops/us) | vector (ops/us) | vector:CPI | vector:branch-misses | vector:LLC-load-misses |
|---|---|---|---|---|---|---|---|---|
| 128 | 0.01 | 1.83 | 0.30 | 3.16 | 17.01 | 0.33 | 0.00 | 0.00 |
| 256 | 0.01 | 1.89 | 0.30 | 3.16 | 16.98 | 0.34 | 0.00 | 0.00 |
| 512 | 0.01 | 1.86 | 0.30 | 3.16 | 15.16 | 0.37 | 0.00 | 0.00 |
| 1024 | 0.01 | 1.86 | 0.30 | 3.15 | 15.07 | 0.38 | 0.01 | 0.00 |
| 2048 | 0.01 | 1.83 | 0.30 | 3.14 | 14.74 | 0.38 | 0.00 | 0.00 |
| 4096 | 0.03 | 1.84 | 0.30 | 2.95 | 13.50 | 0.37 | 0.01 | 0.06 |
| 8192 | 0.13 | 1.88 | 0.31 | 2.72 | 10.06 | 0.44 | 0.02 | 0.36 |
| 16384 | 0.23 | 1.89 | 0.32 | 2.49 | 9.36 | 0.47 | 0.02 | 0.69 |
| 32768 | 0.25 | 1.85 | 0.32 | 2.46 | 9.03 | 0.49 | 0.03 | 0.76 |
Including the L3 cache misses reveals another confounding factor: making the benchmark data unpredictable increases demand on memory bandwidth. Visualising the data the same way as before demonstrates the benefit attainable from using the Vector API.
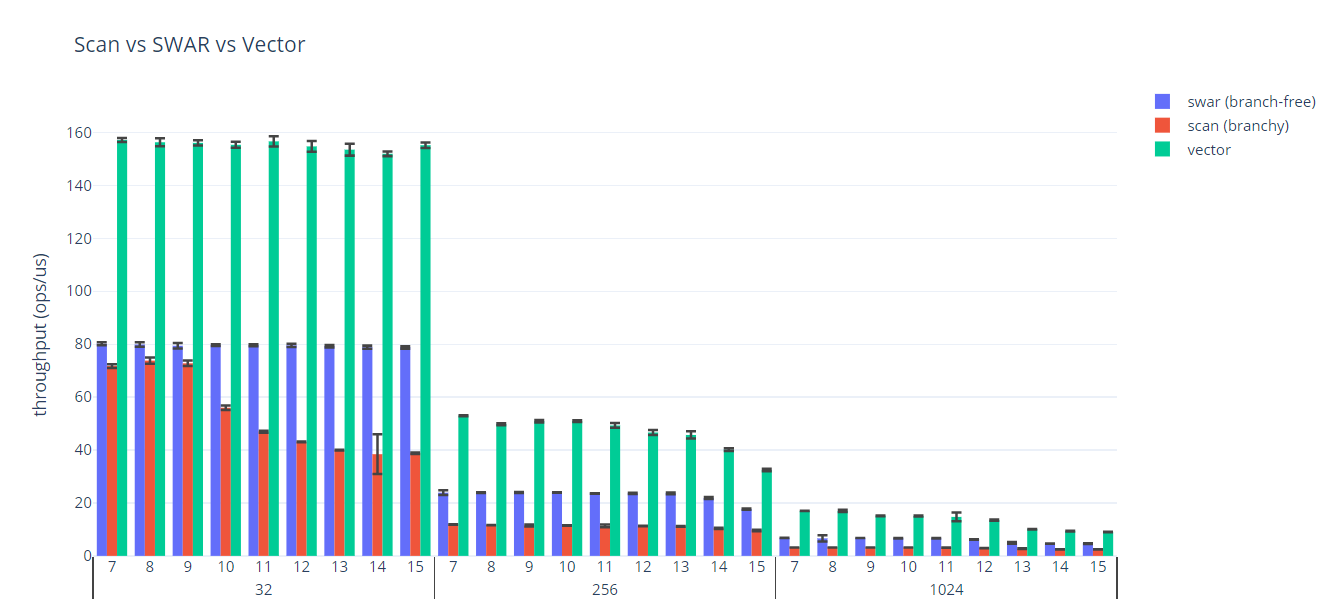
Conclusions
- It’s possible for branchy code to cheat in benchmarks.
- Branch-free code can win benchmarks when data is unpredictable.
- Processing data in chunks is good for performance, but there are incentives for API designers to limit the size of these chunks.
- Taking this to the extreme, vectorisation can outperform scalar code significantly.