5 Mundane Java Performance Tips
Most of the time it isn’t really necessary to optimise software, but this post contains 5 tips to avoid making software written in Java slower for the sake of it.
How to read this post: it didn’t take long for the term premature optimisation to arise after posting this on the Internet. Apart from item 5 (you are burning money if you are still using JDK8), none of this advice is important enough to contort your code to take advantage of. The particular block of code may never get called much, which is where the mantra to fix performance problems once they have been identified comes from. However, for one reason or another, I have looked at probably thousands of profiles of Java code I didn’t write during my career, and all of these things have shown up in profiles several times. That is, these things do cause excessive resource consumption in real applications and libraries. Sometimes, when there is a bottleneck, it indicates a design problem, and preventing the bottleneck from being called so often is usually more effective than speeding up the block of code at the bottleneck. On the other hand, you don’t need to be resizing
HashMaps at least once per request if you have the information to size them properly in hand. If you can, size theHashMapproperly, and it will never become a bottleneck showing up in other people’s profiles down the line.
- Size HashMaps whenever possible
- Use wrappers for composite HashMap keys
- Don’t iterate over Enum.values()
- Use enums instead of constant Strings
- Stop using JDK8
Size HashMaps whenever possible
Even if most of its operations are quite fast, resizing HashMaps is slow and hard to optimise, so the size should be calculated before building the map.
The size parameter does not take the load factor in to account, so the number of elements needs to be divided by the load factor, which is 0.75 by default: multiplying by 4/3 is usually enough.
There are four scenarios in the following benchmark: 10 and 14 keys are inserted into maps with default capacity (16) and maps with a capacity of 24 respectively.
@State(Scope.Benchmark)
public class HashMapResize {
@Param({"10", "14"})
int keys;
@Param({"16", "24"})
int capacity;
@Benchmark
public HashMap<Integer, Integer> loadHashMap() {
HashMap<Integer, Integer> map = new HashMap<>(capacity);
for (int i = 0; i < keys; ++i) {
map.put(i, i);
}
return map;
}
}
The maps have the default load factor of 0.75, so up to 12 keys can be inserted into a map with capacity 16 before a resize. To insert 14 keys without a resize would require an initial capacity of at least 19, but capacities are rounded up to the next power of 2, so 14 keys would end up in a map with a table of capacity 32. Since the initial capacity is rounded up to the next power of 2, it just so happens that when initial capacity 24 is requested, 24 keys would actually fit without a resize.
| Benchmark | Mode | Threads | Samples | Score | Score Error (99.9%) | Unit | Param: capacity | Param: keys |
|---|---|---|---|---|---|---|---|---|
| HashMapResize.loadHashMap | avgt | 1 | 5 | 191.729672 | 9.744065 | ns/op | 16 | 10 |
| HashMapResize.loadHashMap:·gc.alloc.rate.norm | avgt | 1 | 5 | 448.000079 | 0.000010 | B/op | 16 | 10 |
| HashMapResize.loadHashMap | avgt | 1 | 5 | 330.267466 | 14.739395 | ns/op | 16 | 14 |
| HashMapResize.loadHashMap:·gc.alloc.rate.norm | avgt | 1 | 5 | 720.000139 | 0.000025 | B/op | 16 | 14 |
| HashMapResize.loadHashMap | avgt | 1 | 5 | 221.798264 | 97.696476 | ns/op | 24 | 10 |
| HashMapResize.loadHashMap:·gc.alloc.rate.norm | avgt | 1 | 5 | 512.000092 | 0.000038 | B/op | 24 | 10 |
| HashMapResize.loadHashMap | avgt | 1 | 5 | 292.934060 | 13.489139 | ns/op | 24 | 14 |
| HashMapResize.loadHashMap:·gc.alloc.rate.norm | avgt | 1 | 5 | 640.000121 | 0.000016 | B/op | 24 | 14 |
It takes 70% longer to put 14 keys into a HashMap with capacity 16 than it does to insert 10 keys, and allocation rate per constructed map is 60% higher.
Increasing the capacity to 24 saves 11% in allocation rate and 34% in build time per HashMap by avoiding a resize in this benchmark.
Exact numbers will vary but the point is that, if the size of the map can be calculated easily, doing so will save time and reduce allocation rate.
Use wrappers for composite HashMap keys
Whenever a HashMap has composite String keys, use a wrapper instead of concatenating the strings to make a key.
Doing so will make the lookup much faster and reduce allocation rate, as the benchmark below demonstrates.
Two maps, one with concatenated keys and the other with keys in a Pair object are constructed so lookup time can be compared.
@State(Scope.Benchmark)
public class CompositeLookup {
@Param("1024")
int size;
Map<String, Object> concatMap;
Map<Pair, Object> pairMap;
String[] prefixes;
String[] suffixes;
@Setup(Level.Trial)
public void setup() {
prefixes = new String[size];
suffixes = new String[size];
concatMap = new HashMap<>();
pairMap = new HashMap<>();
for (int i = 0; i < size; ++i) {
prefixes[i] = UUID.randomUUID().toString();
suffixes[i] = UUID.randomUUID().toString();
concatMap.put(prefixes[i] + ";" + suffixes[i], i);
// use new String to avoid reference equality speeding up the equals calls
pairMap.put(new Pair(new String(prefixes[i]), new String(suffixes[i])), i);
}
}
@Benchmark
@OperationsPerInvocation(1024)
public void concatenate(Blackhole bh) {
for (int i = 0; i < prefixes.length; ++i) {
bh.consume(concatMap.get(prefixes[i] + ";" + suffixes[i]));
}
}
@Benchmark
@OperationsPerInvocation(1024)
public void wrap(Blackhole bh) {
for (int i = 0; i < prefixes.length; ++i) {
bh.consume(pairMap.get(new Pair(prefixes[i], suffixes[i])));
}
}
}
| Benchmark | Mode | Threads | Samples | Score | Score Error (99.9%) | Unit | Param: size |
|---|---|---|---|---|---|---|---|
| CompositeLookup.concatenate | avgt | 1 | 5 | 158.160452 | 5.622590 | ns/op | 1024 |
| CompositeLookup.concatenate:·gc.alloc.rate.norm | avgt | 1 | 5 | 120.000066 | 0.000010 | B/op | 1024 |
| CompositeLookup.wrap | avgt | 1 | 5 | 43.550144 | 0.932947 | ns/op | 1024 |
| CompositeLookup.wrap:·gc.alloc.rate.norm | avgt | 1 | 5 | 24.000018 | 0.000003 | B/op | 1024 |
Concatenating the keys takes 3.7x longer per lookup and allocates five times more (this depends on the size of the keys though).
The reason wrapping outperforms concatenation is that a String instance caches its hash code, and constructing a new String requires calculation of a new hash code and String’s hash code algorithm also isn’t very efficient.
The difference is actually huge, and I have seen this make a big difference in real applications many times - this idiom should be more common.
Vladimir Sitnikov points out that this pattern turned up as a bottleneck in Spring framework.
Don’t iterate over Enum.values()
An array is allocated every time Enum.values() is called, which can really add up.
If you own the code, and the class won’t be visible to untrusted third parties (i.e. you are the end user), the best thing you can do is preallocate the array and use it instead of Enum.values(), on the basis that your own code won’t mutate it.
Otherwise it can be stashed in a local variable wherever needed, which should alleviate concerns about mutability.
The benchmark below compares iteration over Enum.values(), a preallocated array populated from Enum.values() and over an EnumSet for enums of different sizes.
public class EnumIterationBenchmark {
@Benchmark
public void valuesFour(Blackhole bh) {
for (Four it : Four.values()) {
bh.consume(it.ordinal());
}
}
@Benchmark
public void valuesEight(Blackhole bh) {
for (Eight it : Eight.values()) {
bh.consume(it.ordinal());
}
}
@Benchmark
public void valuesSixteen(Blackhole bh) {
for (Sixteen it : Sixteen.values()) {
bh.consume(it.ordinal());
}
}
@Benchmark
public void cachedFour(Blackhole bh) {
for (Four it : Four.VALUES) {
bh.consume(it.ordinal());
}
}
@Benchmark
public void cachedEight(Blackhole bh) {
for (Eight it : Eight.VALUES) {
bh.consume(it.ordinal());
}
}
@Benchmark
public void cachedSixteen(Blackhole bh) {
for (Sixteen it : Sixteen.VALUES) {
bh.consume(it.ordinal());
}
}
@Benchmark
public void enumSetFour(Blackhole bh) {
for (Four it : EnumSet.allOf(Four.class)) {
bh.consume(it.ordinal());
}
}
@Benchmark
public void enumSetEight(Blackhole bh) {
for (Eight it : EnumSet.allOf(Eight.class)) {
bh.consume(it.ordinal());
}
}
@Benchmark
public void enumSetSixteen(Blackhole bh) {
for (Sixteen it : EnumSet.allOf(Sixteen.class)) {
bh.consume(it.ordinal());
}
}
}
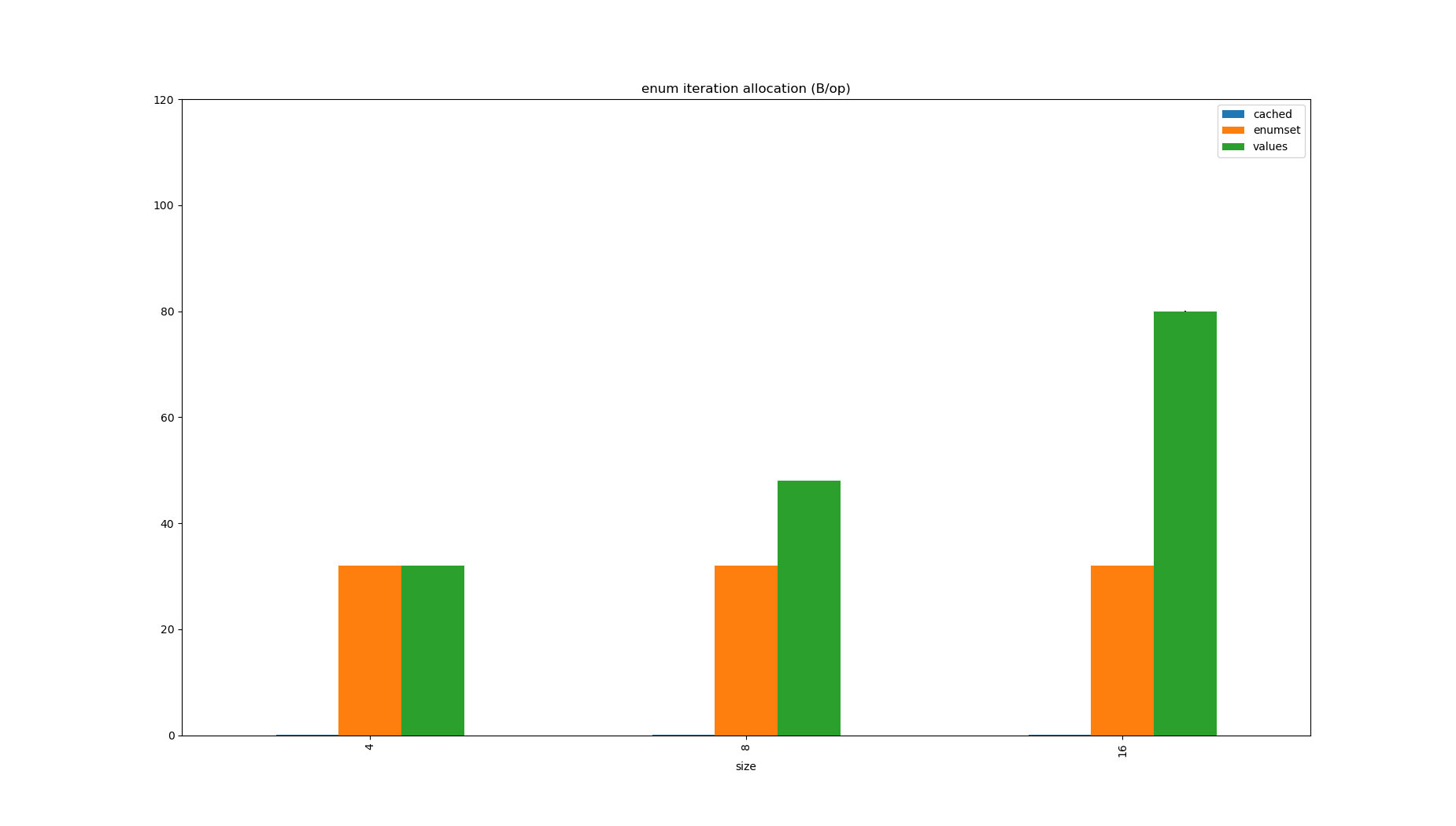
| Benchmark | Mode | Threads | Samples | Score | Score Error (99.9%) | Unit |
|---|---|---|---|---|---|---|
| EnumIterationBenchmark.cachedEight | avgt | 1 | 5 | 28.644844 | 0.171543 | ns/op |
| EnumIterationBenchmark.cachedEight:·gc.alloc.rate.norm | avgt | 1 | 5 | 0.000012 | 0.000000 | B/op |
| EnumIterationBenchmark.cachedFour | avgt | 1 | 5 | 14.774474 | 0.072698 | ns/op |
| EnumIterationBenchmark.cachedFour:·gc.alloc.rate.norm | avgt | 1 | 5 | 0.000006 | 0.000000 | B/op |
| EnumIterationBenchmark.cachedSixteen | avgt | 1 | 5 | 56.613368 | 0.296960 | ns/op |
| EnumIterationBenchmark.cachedSixteen:·gc.alloc.rate.norm | avgt | 1 | 5 | 0.000023 | 0.000000 | B/op |
| EnumIterationBenchmark.enumSetEight | avgt | 1 | 5 | 53.622149 | 1.782352 | ns/op |
| EnumIterationBenchmark.enumSetEight:·gc.alloc.rate.norm | avgt | 1 | 5 | 32.000020 | 0.000001 | B/op |
| EnumIterationBenchmark.enumSetFour | avgt | 1 | 5 | 29.840317 | 1.830070 | ns/op |
| EnumIterationBenchmark.enumSetFour:·gc.alloc.rate.norm | avgt | 1 | 5 | 32.000011 | 0.000001 | B/op |
| EnumIterationBenchmark.enumSetSixteen | avgt | 1 | 5 | 105.247332 | 49.049506 | ns/op |
| EnumIterationBenchmark.enumSetSixteen:·gc.alloc.rate.norm | avgt | 1 | 5 | 32.000040 | 0.000018 | B/op |
| EnumIterationBenchmark.valuesEight | avgt | 1 | 5 | 33.237779 | 2.077222 | ns/op |
| EnumIterationBenchmark.valuesEight:·gc.alloc.rate.norm | avgt | 1 | 5 | 48.000014 | 0.000001 | B/op |
| EnumIterationBenchmark.valuesFour | avgt | 1 | 5 | 16.610465 | 0.906318 | ns/op |
| EnumIterationBenchmark.valuesFour:·gc.alloc.rate.norm | avgt | 1 | 5 | 32.000007 | 0.000000 | B/op |
| EnumIterationBenchmark.valuesSixteen | avgt | 1 | 5 | 56.557226 | 3.012126 | ns/op |
| EnumIterationBenchmark.valuesSixteen:·gc.alloc.rate.norm | avgt | 1 | 5 | 80.000023 | 0.000001 | B/op |
Calling Enum.values() will allocate an easily avoidable 80 bytes per call for a 16 element enum, though doesn’t pose a time penalty.
EnumSets are tiny, so using them reduces allocation rate, but the iteration code is slower than iterating over an array so they don’t offer a good stand in.
I found a case of this which had existed in Spring framework for over a decade earlier in the year, where resolving HTTP status code to Spring’s HttpStatus enum was allocating ~1MB/s at very low request rate.
Use enums instead of constant Strings
There are obvious benefits to using enums instead of strings for constants because enums enforce validation, but they are generally good for performance: even though HashMap is fast, EnumMap is faster.
public class EnumMapBenchmark {
@State(Scope.Benchmark)
public static abstract class BaseState {
@Param("10000")
int size;
@Param("42")
int seed;
int[] randomValues;
@Setup(Level.Trial)
public void setup() {
SplittableRandom random = new SplittableRandom(seed);
randomValues = new int[size];
for (int i = 0; i < size; i++) {
randomValues[i] = random.nextInt(0, Integer.MAX_VALUE);
}
fill(randomValues);
}
abstract void fill(int[] randomValues);
}
@State(Scope.Benchmark)
public static class EnumMapState extends BaseState {
EnumMap<AnEnum, String> map;
AnEnum[] values;
@Override
void fill(int[] randomValues) {
map = new EnumMap<>(AnEnum.class);
values = new AnEnum[randomValues.length];
AnEnum[] enumValues = AnEnum.values();
int pos = 0;
for (int i : randomValues) {
values[pos++] = enumValues[i % enumValues.length];
}
for (AnEnum value : enumValues) {
map.put(value, UUID.randomUUID().toString());
}
}
}
@State(Scope.Benchmark)
public static class MixedState extends BaseState {
EnumMap<AnEnum, String> map;
String[] values;
@Override
void fill(int[] randomValues) {
map = new EnumMap<>(AnEnum.class);
values = new String[randomValues.length];
AnEnum[] enumValues = AnEnum.values();
int pos = 0;
for (int i : randomValues) {
values[pos++] = enumValues[i % enumValues.length].toString();
}
for (AnEnum value : enumValues) {
map.put(value, UUID.randomUUID().toString());
}
}
}
@State(Scope.Benchmark)
public static class HashMapState extends BaseState {
HashMap<String, String> map;
String[] values;
@Override
void fill(int[] randomValues) {
map = new HashMap<>();
values = new String[randomValues.length];
AnEnum[] enumValues = AnEnum.values();
int pos = 0;
for (int i : randomValues) {
values[pos++] = enumValues[i % enumValues.length].toString();
}
for (AnEnum value : enumValues) {
map.put(value.toString(), UUID.randomUUID().toString());
}
}
}
@Benchmark
public void enumMap(EnumMapState state, Blackhole bh) {
for (AnEnum value : state.values) {
bh.consume(state.map.get(value));
}
}
@Benchmark
public void hashMap(HashMapState state, Blackhole bh) {
for (String value : state.values) {
bh.consume(state.map.get(value));
}
}
}
| Benchmark | Mode | Threads | Samples | Score | Score Error (99.9%) | Unit | Param: seed | Param: size |
|---|---|---|---|---|---|---|---|---|
| EnumMapBenchmark.enumMap | avgt | 1 | 5 | 65.225800 | 7.990521 | us/op | 42 | 10000 |
| EnumMapBenchmark.hashMap | avgt | 1 | 5 | 151.394872 | 3.564463 | us/op | 42 | 10000 |
Naturally, there is a one time conversion cost to produce the enum (which ironically uses a HashMap) but once that’s been done it will pay for itself by allowing the use of EnumMap (and EnumSet) unless the value is basically inert.
Don’t contort your code or risk being unable to consume data you don’t control just because EnumMap is fast, but if your data naturally fits an enum, then be sure to make use of EnumMap and EnumSet.
Stop using JDK8
All Java applications use a lot of Strings, and String was just a lot fatter and slower in JDK8.
For example, consider constructing Strings from ASCII encoded byte[]s, which happens a lot if you do things like parse JSON or load classes.
@State(Scope.Benchmark)
public class UTF8Benchmark {
@Param("UTF-8")
String charsetName;
@Param({"4", "20", "200", "2000"})
int size;
Charset charset;
private byte[] bytes;
private String string;
@Setup(Level.Trial)
public void setup() {
this.charset = Charset.forName(charsetName);
this.bytes = asciiBytes(size);
this.string = new String(bytes, charset);
}
@Benchmark
public String stringFromBytes() {
return new String(bytes, charset);
}
@Benchmark
public byte[] bytesFromString() {
return string.getBytes(charset);
}
private static byte[] asciiByted(int size) {
byte[] bytes = new byte[size];
for (int i = 0; i < size; ++i) {
bytes[i] = (byte) (i & 0x7F);
}
return bytes;
}
}
The benchmark was run on JDK8 and JDK11.
ASCII Strings (e.g. class names and metadata or JSON keys) were twice the size on JDK8 because the content was always stored in UTF-16, which explains why the allocation rate was halved in JDK11, but pay attention to how much faster the decoding is too.
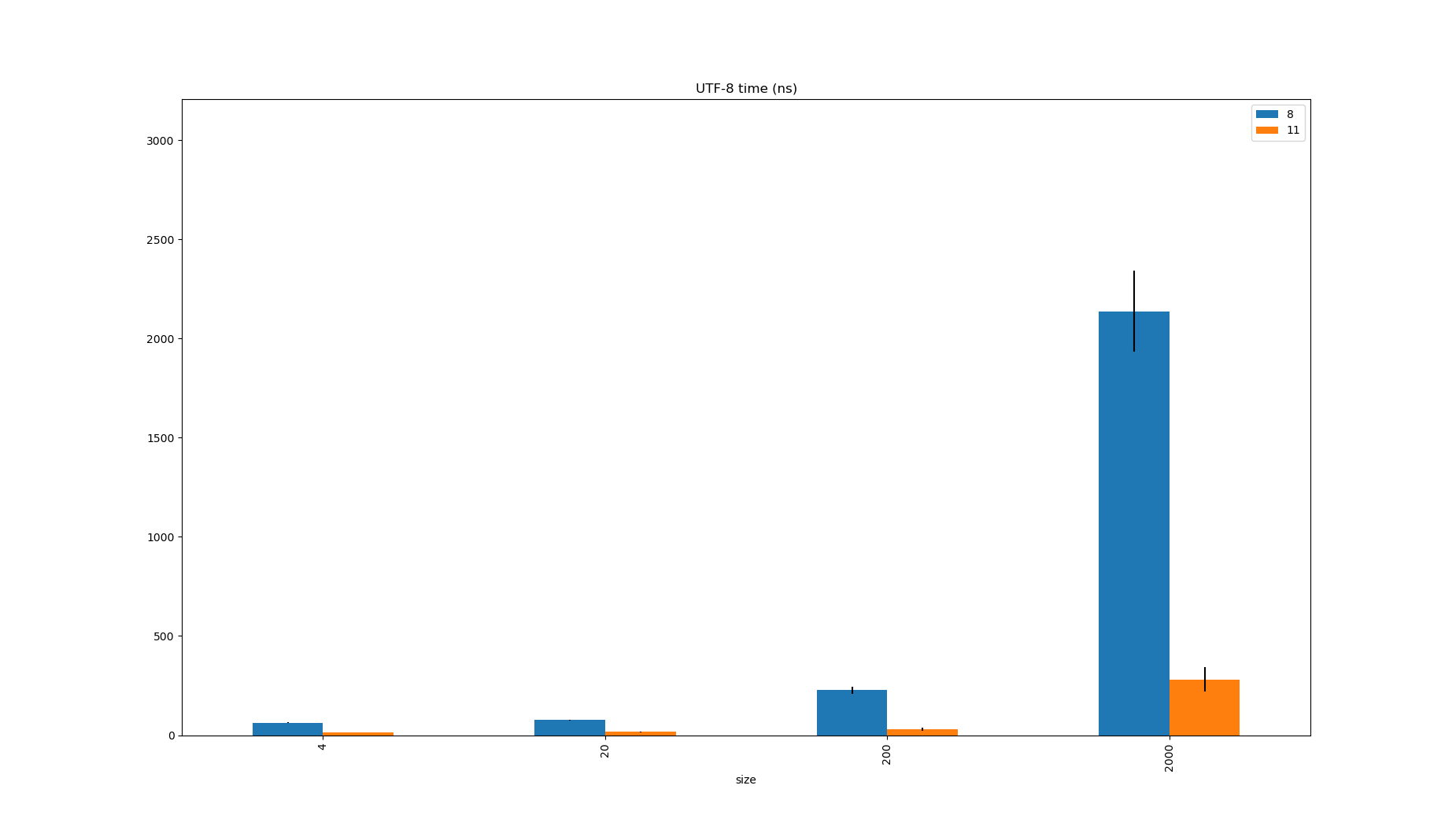
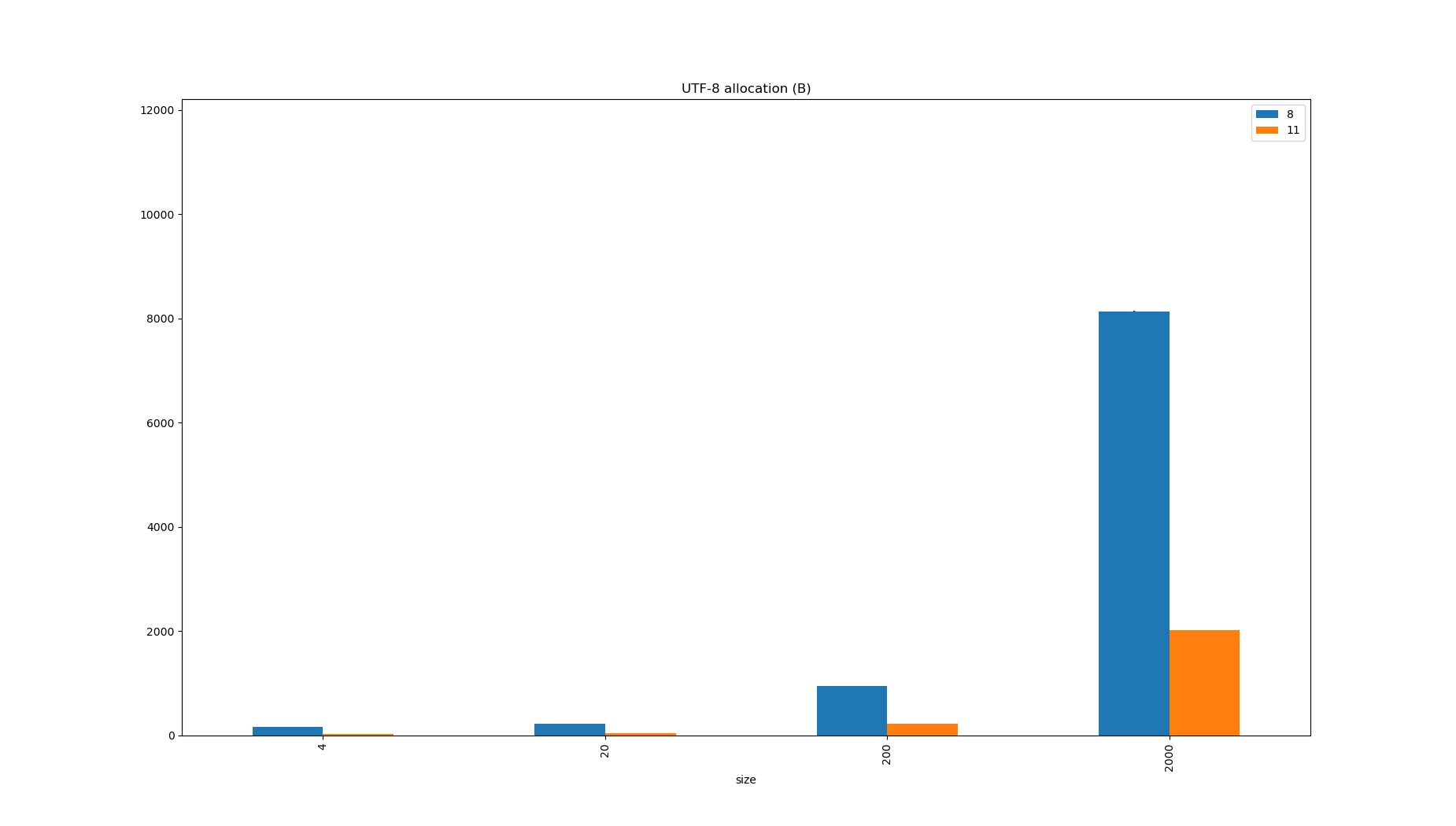
| JDK | Benchmark | Mode | Threads | Samples | Score | Score Error (99.9%) | Unit | Param: charsetName | Param: size |
|---|---|---|---|---|---|---|---|---|---|
| 11 | UTF8Benchmark.stringFromBytes | avgt | 1 | 5 | 18.355847 | 0.674115 | ns/op | UTF-8 | 4 |
| 8 | UTF8Benchmark.stringFromBytes | avgt | 1 | 5 | 51.693575 | 1.610212 | ns/op | UTF-8 | 4 |
| 11 | UTF8Benchmark.stringFromBytes:·gc.alloc.rate.norm | avgt | 1 | 5 | 48.000008 | 0.000001 | B/op | UTF-8 | 4 |
| 8 | UTF8Benchmark.stringFromBytes:·gc.alloc.rate.norm | avgt | 1 | 5 | 88.000023 | 0.000003 | B/op | UTF-8 | 4 |
| 11 | UTF8Benchmark.stringFromBytes | avgt | 1 | 5 | 20.827067 | 3.695586 | ns/op | UTF-8 | 20 |
| 8 | UTF8Benchmark.stringFromBytes | avgt | 1 | 5 | 60.232549 | 1.767569 | ns/op | UTF-8 | 20 |
| 11 | UTF8Benchmark.stringFromBytes:·gc.alloc.rate.norm | avgt | 1 | 5 | 64.000009 | 0.000002 | B/op | UTF-8 | 20 |
| 8 | UTF8Benchmark.stringFromBytes:·gc.alloc.rate.norm | avgt | 1 | 5 | 120.000026 | 0.000004 | B/op | UTF-8 | 20 |
| 11 | UTF8Benchmark.stringFromBytes | avgt | 1 | 5 | 34.451863 | 9.095702 | ns/op | UTF-8 | 200 |
| 8 | UTF8Benchmark.stringFromBytes | avgt | 1 | 5 | 159.427489 | 8.422851 | ns/op | UTF-8 | 200 |
| 11 | UTF8Benchmark.stringFromBytes:·gc.alloc.rate.norm | avgt | 1 | 5 | 240.000014 | 0.000004 | B/op | UTF-8 | 200 |
| 8 | UTF8Benchmark.stringFromBytes:·gc.alloc.rate.norm | avgt | 1 | 5 | 480.000070 | 0.000011 | B/op | UTF-8 | 200 |
| 11 | UTF8Benchmark.stringFromBytes | avgt | 1 | 5 | 285.590238 | 75.077635 | ns/op | UTF-8 | 2000 |
| 8 | UTF8Benchmark.stringFromBytes | avgt | 1 | 5 | 1350.229058 | 69.483579 | ns/op | UTF-8 | 2000 |
| 11 | UTF8Benchmark.stringFromBytes:·gc.alloc.rate.norm | avgt | 1 | 5 | 2040.000118 | 0.000030 | B/op | UTF-8 | 2000 |
| 8 | UTF8Benchmark.stringFromBytes:·gc.alloc.rate.norm | avgt | 1 | 5 | 4080.000601 | 0.000117 | B/op | UTF-8 | 2000 |
It’s a similar story when encoding Strings to byte[] too, which is something your application will do if it does any kind of serialization, logging, or tracing.
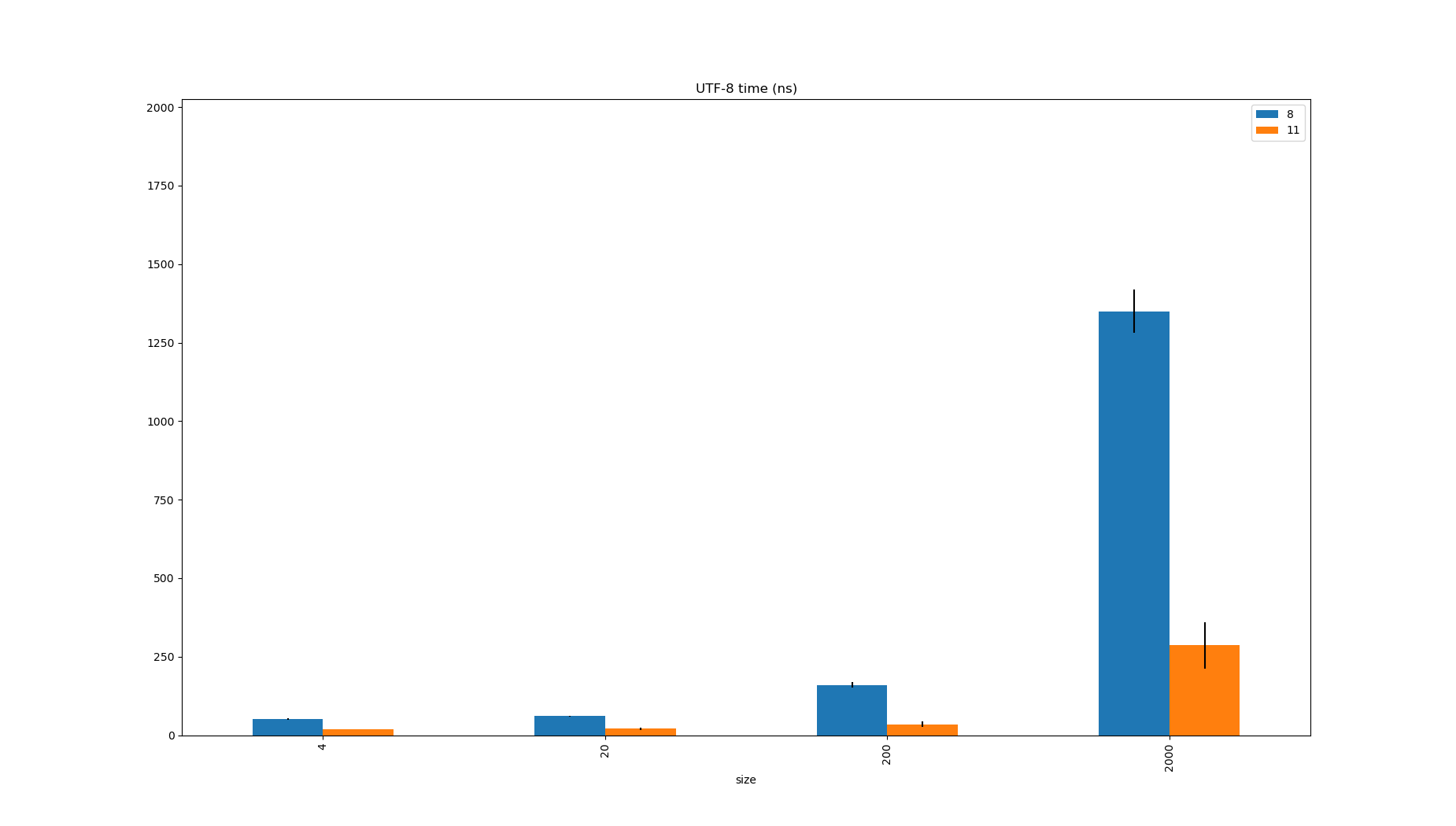
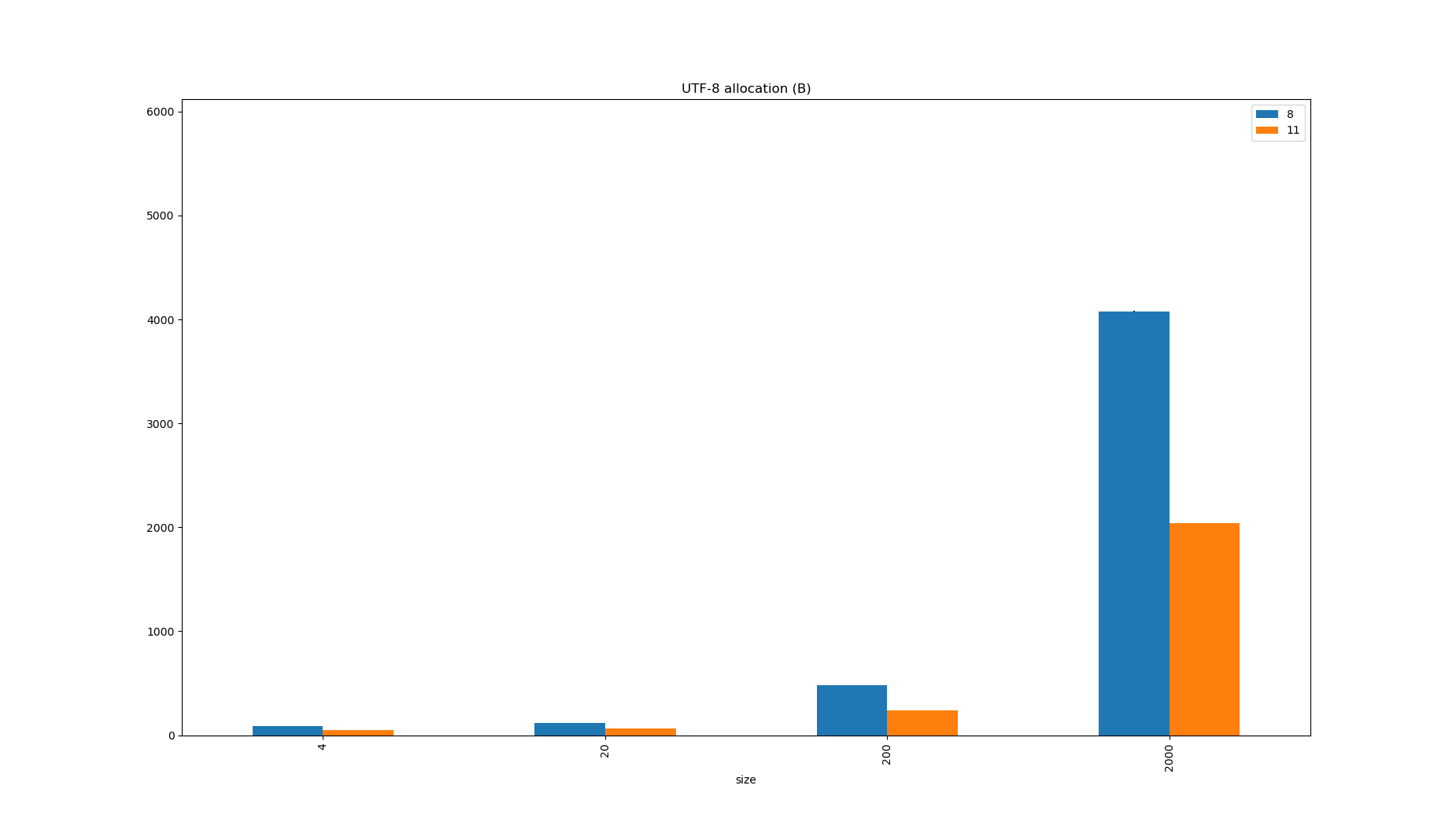
| JDK | Benchmark | Mode | Threads | Samples | Score | Score Error (99.9%) | Unit | Param: charsetName | Param: size |
|---|---|---|---|---|---|---|---|---|---|
| 11 | UTF8Benchmark.bytesFromString | avgt | 1 | 5 | 13.835438 | 0.661028 | ns/op | UTF-8 | 4 |
| 8 | UTF8Benchmark.bytesFromString | avgt | 1 | 5 | 62.958213 | 1.832734 | ns/op | UTF-8 | 4 |
| 11 | UTF8Benchmark.bytesFromString:·gc.alloc.rate.norm | avgt | 1 | 5 | 24.000006 | 0.000001 | B/op | UTF-8 | 4 |
| 8 | UTF8Benchmark.bytesFromString:·gc.alloc.rate.norm | avgt | 1 | 5 | 160.000028 | 0.000004 | B/op | UTF-8 | 4 |
| 11 | UTF8Benchmark.bytesFromString | avgt | 1 | 5 | 17.457885 | 2.175969 | ns/op | UTF-8 | 20 |
| 8 | UTF8Benchmark.bytesFromString | avgt | 1 | 5 | 75.760063 | 3.000610 | ns/op | UTF-8 | 20 |
| 11 | UTF8Benchmark.bytesFromString:·gc.alloc.rate.norm | avgt | 1 | 5 | 40.000007 | 0.000002 | B/op | UTF-8 | 20 |
| 8 | UTF8Benchmark.bytesFromString:·gc.alloc.rate.norm | avgt | 1 | 5 | 224.000033 | 0.000004 | B/op | UTF-8 | 20 |
| 11 | UTF8Benchmark.bytesFromString | avgt | 1 | 5 | 30.758900 | 8.336043 | ns/op | UTF-8 | 200 |
| 8 | UTF8Benchmark.bytesFromString | avgt | 1 | 5 | 227.269922 | 18.536450 | ns/op | UTF-8 | 200 |
| 11 | UTF8Benchmark.bytesFromString:·gc.alloc.rate.norm | avgt | 1 | 5 | 216.000013 | 0.000003 | B/op | UTF-8 | 200 |
| 8 | UTF8Benchmark.bytesFromString:·gc.alloc.rate.norm | avgt | 1 | 5 | 936.000100 | 0.000014 | B/op | UTF-8 | 200 |
| 11 | UTF8Benchmark.bytesFromString | avgt | 1 | 5 | 280.886995 | 61.136388 | ns/op | UTF-8 | 2000 |
| 8 | UTF8Benchmark.bytesFromString | avgt | 1 | 5 | 2138.703149 | 203.825640 | ns/op | UTF-8 | 2000 |
| 11 | UTF8Benchmark.bytesFromString:·gc.alloc.rate.norm | avgt | 1 | 5 | 2016.000116 | 0.000024 | B/op | UTF-8 | 2000 |
| 8 | UTF8Benchmark.bytesFromString:·gc.alloc.rate.norm | avgt | 1 | 5 | 8136.000937 | 0.000113 | B/op | UTF-8 | 2000 |
These operations are so fundamental that it’s impossible to escape them.